TOP > サンプル/関数 > * [...]

概要
PDFページ上の全テキストを抽出します。テキストはページ単位に以下の内容に編集します。
- 行単位の文字列
- 行単位の文字列の座標(計算で出したY座標のみ)
- ヘッダー(連続するページ上の最上部行。連続行有り)
- フッター(連続するページ上の最終行。連続行有り)
上記を配列で返します。全て計算で出しているので、期待しない結果が出る可能性が有ります。
詳細
PDFファイルからテキストと同時に取得できる情報は座標(X、Y)だけです。行(行番号)と言う情報は取得できません。英語ならば単語単位、日本語ならば1文字単位の座標(X、Y)で取得します。
参照:PDF上のテキストとその座標
当関数は、同じ行なのか、連続する1行のテキストなのかを座標を見て計算しています。行番号はページ上部からテキストの出現順に1,2,3行目としています。
ヘッダー、フッター以外の本文のみのテキスト検索にも使用できると思っています。
処理動作を変更する定数をいくつか備えていますが、最初はPDFファイルのパスだけを指定して、他はデフォルトで試して下さい。
座標はページ左下を基点とします。
抽出されるテキストの順番
プログラムでは画面上部から表示される順番でテキストの取得はできません。画面トップに表示さていたテキストが途中や最後の場合も有ります。同じ行内のテキストでも順番が前後する場合も有ります。これはPDFファイルの作成時の内容によって変わるみたいです。理由の詳細は不明です。
各テキストは画面表示上の座標(X、Y)を持っています。よって、テキストの順序が前後しても、画面表示では全く問題が出ません。
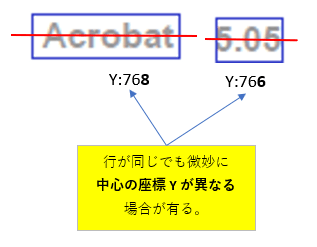
しかし、順番の前後するテキストをプログラムで扱うとなると問題が出てきます。この関数は座標を見て、画面表示の順(上から下へ、左から右へ)で各テキストを並び替えます。但し、並び替えると問題が出るケースもあります。表内のテキストや索引などのように横に行が複数存在する場合です。並び替えるとテキストのY座標が同じ場合は同じ行と判断してしまうからです。当関数では並び替えをしない指定も出来ます(非推奨!)。
同じ行のテキストと判断する条件
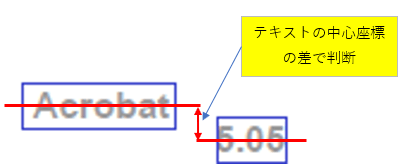
PDF上に以下のようなテキストが存在するとします。
これをプログラムで抽出すると、以下の青枠の単位で分割されて返されます。
「Acrobat 5.05」は「Acrobat」と「5.05」に分割されます。分割方法の指示や変更は出来ません。
当関数は同じ行のテキストと判断する条件を各テキスト横の中心座標の高さの差で行います。
各テキストの中心座標の Y 座標の差が、頁内のテキストの平均的な高さ(Y座標)の1/4の範囲に有れば、同じ行のテキストと判断します。1/4は経験則から出した独自の値です(変更可能:C_DEV 定数)。
ヘッダー、フッターと判断する条件
以下の条件を全て必要とします。
- 1行目から次ページと同じ位置に同じテキストが存在する時にヘッダーとします。最終行から次ページと同じ位置に同じテキストが存在する時にフッターとします。ヘッダーは下の行へ、フッターは上の行へ連続行の判断もします。
- 数字と記号以外のテキストが同じ。
変化するページ番号を無視する為の条件です。「年月日」の文字も無視します。テキストの横方向のX座標は見ません。
- 前後するページ上のテキストの中心座標Yの差がほぼ同じ。
テキストの中心座標Yの差は前ページのテキストの平均的な高さの1/4です(変更可能:C_DEV 定数)。
- 次ページの同じ位置に同じテキストが存在しなくても、ヘッダー行と判断した真下(直下)にある行もヘッダーと見なします。フッターも同様に、次ページの同じ位置に同じテキストが存在しなくても、フッターと判断した真上(直上)にある行もフッターとします。これは1ページ上にしか存在しないヘッダー、又はフッターも取り込む為の機能です。1行でもヘッダー、又はフッターが存在した時に機能します。
但し、この機能はデフォルトでは無効です。定数で有効に変更できます。
- ヘッダー、又はフッターと判断した行から離れた位置にある行は判断はしません。稀に本文のトップ行が同じ文字、同じ位置に有る場合があります。デフォルトではテキストの平均高さYの2.5倍以上離れていると無視します。フッターも同様です。
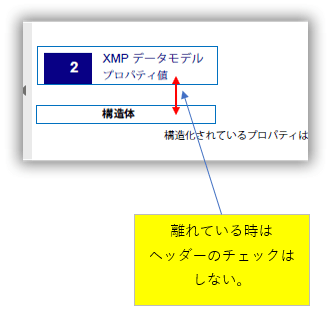
例:
「 XMPデータモデル」行は次ページ上の同じ位置に同じテキストが存在するので、ヘッダーと判断しました。
「プロパティ値」行は次ページの同じ位置にテキストが存在しなくてもヘッダーとして見ることが出来ます(4.の機能)。但し、デフォルでは、この機能は無効になっています。
「構造体」行はヘッダー行の「プロパティ値」から離れているので、ヘッダーの判断はしません(5.の機能)。
「4.」も「5.」もVBAソース内の定数で機能オン・オフに出来ます。
機能
- 指定したPDFの全テキストを抽出します。
- 抽出したテキストはY座標に従って並び替えます(推奨)。
並び替えをしない設定(bSortY = False)も出来ます。
- テキストのY座標をもとに1行のテキストに結合します。
結合する前にX座標の順にテキストを並び替えます(推奨)。
並び替えをしない設定(bSortX = False)も出来ます。
- 条件を満たした1行目をヘッダー、最終行をフッターとします。連続行も判断します。
形式
Public Function OutSquareRects( _
ByVal sInFilePathIn As String, _
ByRef sOutData() As PageLineZahyo) As Boolean
- 第1引数(sInFilePathIn):PDFのフルパスを指定します。
- 第2引数(sOutData):処理の結果です。
詳細は以下の「第2引数:sOutDataの詳細」を参照。
第2引数:sOutDataの詳細
処理結果が「sOutData() As PageLineZahyo」配列に返されます。
'処理の結果
Private Type PageLineZahyo
iLineCount As Long '行数:1~
sLineData(C_MAXLINE) As String '行のテキスト
iLineDataY(C_MAXLINE) As Long '行の中央Y座標
iHeaderCount As Long 'ヘッダー件数:1~
iFooterCount As Long 'フッター件数:1~
bHeaderFlag(C_MAXLINE) As Boolean 'Trueはヘッダー行
bFooterFlag(C_MAXLINE) As Boolean 'Trueはフッター行
'以下は作業用、デバッグ用
bHeaderST(C_MAXLINE) As Boolean 'Trueはヘッダー行・真下
bFooterST(C_MAXLINE) As Boolean 'Trueはフッター行・真上
iAveTextY As Long 'テキストの平均的な高さY
iTextCount As Long '座標を持ったテキスト数
End Type '注:文字数の合計では無い
- iCountLine:ページ内の行数。1は1行。-1、0はゼロ行。
- sLineData( ):ページ内の行データ。配列で返します。
- iLineDataY( ):行データの中心座標のY値。
- iHeaderCount:ヘッダーの数。0は無し。1~
- iFooterCount:フッターの数。0は無し。1~
- bHeaderFlag( ):ヘッダーの有無。sLineDataと同じ位置がTrueならヘッダー。見方は以下を参照。
- bFooterFlag( ):フッターの有無。sLineDataと同じ位置がTrueならフッター。見方は以下を参照。
上記以外は作業用、デバッグ用の変数です。
フッターを見る時は iCountLine の値で配列の最後が判断できます。
戻り値
- True : 正常
- False : エラー。第一引数のファイルがPDFで無い等。
動作検証した環境
- Windows 10 64bit Pro
- Adobe Acrobat XI Pro (バージョン 11.0.23)
- MS Office - Excel 2007 - VBA
関数のソース - VBA
VBAソースのダウンロードファイルは公開していません。以下をコピペしてご確認下さい。
参照設定が2つ必要です。
001 Option Explicit
002
003 '**************************************************
004 '
005 ' Create : 2023/03/07
006 ' Update : 2023/03/12
007 '
008 ' ★の値はテストで出した結果。
009 '**************************************************
010
011 '全体で使用
012 Private Const C_MAXLINE As Long = 200 'ページ中の最大行数
013 Private Const C_DEV As Long = 4 '差計算時の分母
014
015 'Sort_TextData で使用
016 Private Const C1_Y_FIX As Boolean = True 'Y座標の修正
017 Private Const C1_SA As Long = 3 '★差の範囲 Y座標
018 Private Const C1_SORTX As Boolean = True 'X軸ソートの実行
019 Private Const C1_SORTY As Boolean = True 'Y軸ソートの実行
020
021 'Get_Header_Footer で使用
022 '行間が長い行はチェック対象から外す。
023 'True:外す False:外さない
024 Private Const C2_LONG_HD As Boolean = False 'ヘッダー
025 Private Const C2_LONG_FT As Boolean = False 'フッター
026 Private Const C2_LONG_BAI = 2.5 '★行(高さ)の倍率
027 '真下、真上の行はヘッダー、フッターに取り込む
028 'True:取り込む False:取り込まない
029 Private Const C2_SHORT_HD As Boolean = True 'ヘッダーの真下
030 Private Const C2_SHORT_FT As Boolean = True 'フッターの真上
031 Private Const C2_SHORT_BAI = 1.3 '★行(高さ)の倍率
032
033 '処理の結果
034 Private Type PageLineZahyo
035 iLineCount As Long '行数:1~
036 sLineData(C_MAXLINE) As String '行のテキスト
037 iLineDataY(C_MAXLINE) As Long '行の中央Y座標
038 iHeaderCount As Long 'ヘッダー件数:1~
039 iFooterCount As Long 'フッター件数:1~
040 bHeaderFlag(C_MAXLINE) As Boolean 'Trueはヘッダー行
041 bFooterFlag(C_MAXLINE) As Boolean 'Trueはフッター行
042
043 '以下は作業用、デバッグ用
044 bHeaderST(C_MAXLINE) As Boolean 'Trueは真下のヘッダー行
045 bFooterST(C_MAXLINE) As Boolean 'Trueは真上のフッター行
046 iAveTextY As Long 'テキストの平均的な高さY
047 iTextCount As Long '座標を持ったテキスト数
048 End Type '注:文字数の合計では無い
049
050 'PDFファイル内のテキストとその座標(一時作業用)
051 Private Type TextZahyo
052 sText As String 'テキスト(編集済み)
053 sTextOrg As String 'テキスト(オリジナル)
054 '※Trime前の状態
055 sTop As String '上部 座標
056 sBottom As String '下部 座標
057 sLeft As String '左 座標
058 sRight As String '右 座標
059 iLineNo As Long '行番号
060 iCenterX As Long '中心座標 X
061 iCenterY As Long '中心座標 Y
062 End Type
063
064 'Acrobat JavaScriptから取得のQuads座標
065 Private Enum JsZahyo
066 iTop = 1
067 iBottom = 5
068 iLeft = 0
069 iRight = 2
070 End Enum
071 '※ 0[Left] 1[Top] 2[Right] 3[Top]
072 '※ 4[Left] 5[Bottom] 6[Right] 7[Bottom]
073
074
075 '**************************************************
076 '
077 ' 関数を呼び出すテスト用
078 '
079 ' Create : 2023/03/07
080 '
081 '**************************************************
082 Sub Main_Test()
083 Dim bRet As Boolean '関数の戻り値
084 Dim sInFilePathIn As String 'PDFファイル
085 Dim sOutData() As PageLineZahyo 'テキストと座標
086
087 'PDF内の全テキストと座標を取得
088 sInFilePathIn = ThisWorkbook.Path & "\Test22.pdf"
089 bRet = OutSquareRects(sInFilePathIn, sOutData)
090 If bRet = False Then Exit Sub
091
092 '=====================================
093 '結果をテキスト出力し、メモ帳も起動する
094 Call WriteLog(sInFilePathIn, sOutData)
095 End Sub
096
097 '**************************************************
098 '
099 ' PDF内の全テキストを抽出し、行データを作成する。
100 ' ヘッダー、フッターの情報も作成する。
101 '
102 ' Create : 2023/02/28
103 ' Update : 2023/03/11
104 '
105 ' 引数1 : sInFilePathIn As String (IN)
106 ' 入力するPDFファイルのフルパス
107 '
108 ' 引数2 : sOutData() As PageLineZahyo (OUT)
109 ' PDFファイル内の
110 ' ・行とそのY座標
111 ' ・ヘッダー、フッター
112 '
113 ' 戻り値 : True 正常
114 ' False エラー、PDFが無い、等
115 '
116 ' 参照設定:
117 ' Acrobat (Adobe Acrobat **.* Type Library)
118 ' AFormAut 1.0 Type Library
119 '
120 '**************************************************
121 Public Function OutSquareRects( _
122 ByVal sInFilePathIn As String, _
123 ByRef sOutData() As PageLineZahyo) As Boolean
124
125 'On Error GoTo Err_OutSquareRects:
126 OutSquareRects = True
127 Dim start As Double: start = Timer
128
129 Dim i1 As Long
130 Dim i2 As Long
131 Dim iPageNo As Long
132 Dim iPageEnd As Long
133 Dim bRet As Boolean
134
135 Dim sAJS As String
136 Dim sReturn As String
137 Dim sJsText As String
138 Dim sJsTextOrg As String
139 Dim sJsWk2() As String
140 Dim sJsWk3() As String
141 Dim sJsQuads() As String
142
143 Dim sTextDT() As TextZahyo '作業用
144
145 'テキストの座標を取得するAcrobat JavScript
146 Const sAcrobatJavaScript = _
147 "var sOut='';" & _
148 "var numWords = this.getPageNumWords(@P);" & _
149 "for ( var j = 0; j < numWords; j++) {" & _
150 " nthWord = this.getPageNthWord(@P,j,false);" & _
151 " aQuads = this.getPageNthWordQuads(@P,j);" & _
152 " sOut=sOut + j + '\b' + nthWord + " & _
153 "'\b' + aQuads + '\t';" & _
154 "}" & _
155 "event.value=sOut;"
156 '※下記の特殊文字はデータの区切りに使用
157 ' \b:バックスペース
158 ' \t:タブ
159
160 If Dir$(sInFilePathIn, vbNormal) = "" Then
161 MsgBox sInFilePathIn & vbCrLf & _
162 "ファイルが存在しない。", _
163 vbOKOnly + vbCritical, "実行エラー"
164 OutSquareRects = False
165 Exit Function
166 End If
167
168 'Acrobatオブジェクトの定義&作成
169 Dim objAcroApp As New Acrobat.AcroApp
170 Dim objAcroAVDoc As New Acrobat.AcroAVDoc
171 Dim objAcroPDDoc As New Acrobat.AcroPDDoc
172 Dim objAFormApp As AFORMAUTLib.AFormApp
173 Dim objAFormFields As AFORMAUTLib.Fields
174
175 '前回のエラー終了時の事前対応
176 objAcroApp.CloseAllDocs
177 objAcroApp.Hide '稀にデスクトップに表示されるので隠す
178
179 'PDFファイルを開く
180 If objAcroAVDoc.Open(sInFilePathIn, "") = False Then
181 MsgBox "Open出来ません。" & vbCrLf & sInFilePathIn, _
182 vbOKOnly + vbCritical, "実行エラー"
183 OutSquareRects = False
184 GoTo Skip_OutSquareRects_END:
185 End If
186
187 Application.Cursor = xlWait 'マウスポインターを砂時計
188 Set objAcroPDDoc = objAcroAVDoc.GetPDDoc
189 iPageEnd = objAcroPDDoc.GetNumPages - 1
190 Set objAFormApp = CreateObject("AFormAut.App")
191 Set objAFormFields = objAFormApp.Fields
192 Set objAcroPDDoc = objAcroAVDoc.GetPDDoc
193
194 'ページ単位のテキストデータ
195 ReDim sOutData(iPageEnd) As PageLineZahyo
196
197 For iPageNo = 0 To iPageEnd
198
199 DoEvents 'CPUを一時的に返す
200 '頁単位で全文字列+座標を抽出
201
202 'Acrobat JavaScriptの編集
203 sAJS = sAcrobatJavaScript
204 sAJS = Replace(sAJS, "@P", iPageNo)
205 'Acrobat JavaScript の実行
206 sReturn = objAFormFields.ExecuteThisJavascript(sAJS)
207 sJsWk2 = Split(sReturn, vbTab)
208
209 Debug.Print "Page=" & iPageNo + 1 & _
210 " Start-Time=" & Time & " Count=" & _
211 UBound(sJsWk2) + 1
212
213 '結果の編集
214 i2 = -1
215 If UBound(sJsWk2) >= 0 Then
216 ReDim sTextDT(UBound(sJsWk2)) As TextZahyo
217 End If
218
219 For i1 = 0 To UBound(sJsWk2)
220 If sJsWk2(i1) = "" Then Exit For
221
222 sJsWk3 = Split(sJsWk2(i1), vbBack)
223 sJsQuads = Split(sJsWk3(2), ",")
224 sJsText = sJsWk3(1)
225 sJsText = Replace(sJsText, vbCr, "")
226 sJsText = Replace(sJsText, vbLf, "")
227 sJsTextOrg = sJsText
228 sJsText = Trim$(sJsText)
229 If sJsText <> "" Then
230 i2 = i2 + 1
231 With sTextDT(i2)
232 .sText = sJsText
233 .sTextOrg = sJsTextOrg
234 .sTop = sJsQuads(JsZahyo.iTop)
235 .sBottom = sJsQuads(JsZahyo.iBottom)
236 .sLeft = sJsQuads(JsZahyo.iLeft)
237 .sRight = sJsQuads(JsZahyo.iRight)
238 '初期化
239 .iLineNo = -1
240 .iCenterX = -1
241 .iCenterY = -1
242 End With
243 End If
244 Next i1
245
246 sOutData(iPageNo).iTextCount = i2
247 If i2 >= 0 Then
248 ReDim Preserve sTextDT(i2) As TextZahyo
249
250 '▼全テキストの[平均の高さ]と[中心座標]を求める
251 bRet = EditYobiData(iPageNo, sOutData(), sTextDT)
252 If bRet = False Then
253 OutSquareRects = False
254 Exit For
255 End If
256
257 '▼テキストの中心座標を基に全テキストのソートを行う
258 bRet = Sort_TextData(iPageNo, sOutData(), sTextDT)
259 If bRet = False Then
260 OutSquareRects = False
261 Exit For
262 End If
263
264 '▼テキストデータから行データを作成
265 bRet = MargTextLine(iPageNo, sOutData(), sTextDT)
266 If bRet = False Then
267 OutSquareRects = False
268 Exit For
269 End If
270 End If
271
272 Next iPageNo
273
274 '▼ヘッダー、フッターを抽出
275 bRet = Get_Header_Footer(sOutData)
276 ' If bRet = False Then Exit Sub
277
278 Application.Cursor = xlDefault 'マウスポインターを戻す
279 'PDFファイルを閉じる
280 If objAcroAVDoc.Close(False) = False Then
281 MsgBox "AVDocオブジェクトはClose出来ませんでした", _
282 vbOKOnly + vbCritical, "実行エラー"
283 OutSquareRects = False
284 End If
285
286 Skip_OutSquareRects_END:
287
288 On Error Resume Next 'これ以降は強制実行
289
290 Application.Cursor = xlDefault 'マウスポインターを戻す
291 '変更しないで閉じます。
292 bRet = objAcroAVDoc.Close(False)
293 'Acrobatアプリケーションの終了
294 objAcroApp.Hide
295 objAcroApp.Exit
296 'オブジェクトの強制開放
297 Set objAFormFields = Nothing
298 Set objAFormApp = Nothing
299 Set objAcroPDDoc = Nothing
300 Set objAcroAVDoc = Nothing
301 Set objAcroApp = Nothing
302
303 Debug.Print "Total Time = " & Timer - start & _
304 " PageCnt = " & iPageEnd + 1
305
306 Exit Function
307
308 Err_OutSquareRects:
309 MsgBox "処理は以下の理由で中断しました。" & vbCrLf & _
310 vbCrLf & err.Number & vbCrLf & err.Description, _
311 vbOKOnly + vbCritical, "OutSquareRects:実行エラー"
312 OutSquareRects = False
313 GoTo Skip_OutSquareRects_END:
314 End Function
315
316 '**************************************************
317 '
318 ' データの中間加工
319 '
320 ' ・全テキストの平均・高さを求める
321 ' ・全テキストの中心座標を求める
322 '
323 ' Create : 2023/03/07
324 '
325 ' ※ココで求める値は整数値で十分
326 '
327 '**************************************************
328 Private Function EditYobiData( _
329 ByVal iPageNo As Long, _
330 ByRef sOutData() As PageLineZahyo, _
331 ByRef sTextDT() As TextZahyo) As Boolean
332
333 EditYobiData = True
334
335 Dim i1 As Long
336 Dim iAll As Long 'テキストの高さの集計
337 Dim iHi As Long '計算用作業
338
339 iAll = 0
340 For i1 = 0 To UBound(sTextDT)
341 With sTextDT(i1)
342 iHi = Round(val(.sTop) - val(.sBottom))
343 'テキストの高さの集計
344 iAll = iAll + iHi
345 'テキストの中心座標
346 .iCenterY = Round(val(.sTop) - (iHi / 2))
347 iHi = val(.sRight) - val(.sLeft)
348 .iCenterX = Round(val(.sRight) - (iHi / 2))
349 '初期化
350 .iLineNo = -1
351 End With
352 Next i1
353
354 With sOutData(iPageNo)
355 If .iTextCount = -1 Then
356 .iAveTextY = -1
357 Else
358 'ページ単位のテキストの平均的な高さ
359 .iAveTextY = Round(iAll / (.iTextCount + 1))
360 End If
361 End With
362
363 End Function
364
365 '**************************************************
366 '
367 ' テキストの中心座標を基に全テキストをソートする
368 '
369 ' Create : 2023/03/08
370 ' Update : 2023/03/12
371 '
372 ' 注:(C1_Y_FIX=True)で行間(座標Y)が小さい場合(差:3)は
373 ' 先頭行と同じ座標Yに強制修正する。同じ行内でも
374 ' 高さが少し異なるテキストを同じ行とする為の処理です。
375 ' このようなテキストは非常に多い。
376 '**************************************************
377 Private Function Sort_TextData( _
378 ByVal iPageNo As Long, _
379 ByRef sOutData() As PageLineZahyo, _
380 ByRef sTextDT() As TextZahyo) As Boolean
381
382 Sort_TextData = True
383
384 Dim iSa As Long '計算の差
385 Dim i1 As Long
386 Dim i2 As Long
387 Dim iEndInx As Long
388 Dim w_sText As String 'テキスト
389 Dim w_sTextOrg As String 'テキスト(オリジナル)
390 Dim w_sTop As String '上部 座標
391 Dim w_sBottom As String '下部 座標
392 Dim w_sLeft As String '左 座標
393 Dim w_sRight As String '右 座標
394 Dim w_iLineNo As Long '行番号
395 Dim w_iCenterX As Long '中心座標 X
396 Dim w_iCenterY As Long '中心座標 Y
397 Dim iLineSeqNo As Long '行番号
398 Dim iHeightAve As Long 'テキストの平均的な高さ
399
400 iEndInx = sOutData(iPageNo).iTextCount
401
402 '▼Y軸座標でソート
403 If C1_SORTY Then
404 For i1 = 0 To iEndInx - 1
405 For i2 = i1 + 1 To iEndInx
406 If sTextDT(i1).iCenterY < sTextDT(i2).iCenterY Then
407 w_sText = sTextDT(i1).sText
408 w_sTextOrg = sTextDT(i1).sTextOrg
409 w_sTop = sTextDT(i1).sTop
410 w_sBottom = sTextDT(i1).sBottom
411 w_sLeft = sTextDT(i1).sLeft
412 w_sRight = sTextDT(i1).sRight
413 w_iCenterX = sTextDT(i1).iCenterX
414 w_iCenterY = sTextDT(i1).iCenterY
415
416 sTextDT(i1).sText = sTextDT(i2).sText
417 sTextDT(i1).sTextOrg = sTextDT(i2).sTextOrg
418 sTextDT(i1).sTop = sTextDT(i2).sTop
419 sTextDT(i1).sBottom = sTextDT(i2).sBottom
420 sTextDT(i1).sLeft = sTextDT(i2).sLeft
421 sTextDT(i1).sRight = sTextDT(i2).sRight
422 sTextDT(i1).iCenterX = sTextDT(i2).iCenterX
423 sTextDT(i1).iCenterY = sTextDT(i2).iCenterY
424
425 sTextDT(i2).sText = w_sText
426 sTextDT(i2).sTextOrg = w_sTextOrg
427 sTextDT(i2).sTop = w_sTop
428 sTextDT(i2).sBottom = w_sBottom
429 sTextDT(i2).sLeft = w_sLeft
430 sTextDT(i2).sRight = w_sRight
431 sTextDT(i2).iCenterX = w_iCenterX
432 sTextDT(i2).iCenterY = w_iCenterY
433 End If
434 Next i2
435 Next i1
436 '微妙な座標Y誤差の修正
437 If C1_Y_FIX Then
438 For i1 = 0 To iEndInx - 1
439 iSa = Abs(sTextDT(i1).iCenterY - _
440 sTextDT(i1 + 1).iCenterY)
441 If (0 < iSa) And (iSa <= C1_SA) Then
442 sTextDT(i1 + 1).iCenterY = _
443 sTextDT(i1).iCenterY
444 End If
445 Next i1
446 End If 'End IF (C1_Y_FIX)
447 End If 'End If (bSortY)
448
449 '▼行番号を追加する。Y座標で判断する。
450 If sOutData(iPageNo).iTextCount = -1 Then
451 sOutData(iPageNo).iLineCount = -1
452 Else
453 iLineSeqNo = 1
454 iHeightAve = Round(sOutData(iPageNo).iAveTextY / C_DEV)
455 '※下記にしたら影響するのは本文のみ。
456 ' iHeightAve = 0
457 For i1 = 0 To iEndInx - 1
458 sTextDT(i1).iLineNo = iLineSeqNo
459 For i2 = i1 + 1 To iEndInx
460 If Abs((sTextDT(i1).iCenterY - _
461 sTextDT(i2).iCenterY)) <= iHeightAve Then
462 '行番号を設定
463 sTextDT(i2).iLineNo = iLineSeqNo
464 Else
465 i1 = i2 - 1
466 iLineSeqNo = iLineSeqNo + 1
467 Exit For
468 End If
469 Next i2
470 Next i1
471 If sTextDT(iEndInx).iLineNo = -1 Then
472 sTextDT(iEndInx).iLineNo = iLineSeqNo
473 End If
474 sOutData(iPageNo).iLineCount = iLineSeqNo
475 End If
476
477 '▼行番号単位でX軸ソート
478 If C1_SORTX Then
479 If sOutData(iPageNo).iTextCount <> -1 Then
480 iLineSeqNo = -1
481 For i1 = 0 To iEndInx - 1
482 For i2 = i1 + 1 To iEndInx
483 If sTextDT(i1).iLineNo <> sTextDT(i2).iLineNo _
484 Then Exit For
485 If sTextDT(i1).iCenterX > sTextDT(i2).iCenterX Then
486 w_sText = sTextDT(i1).sText
487 w_sTextOrg = sTextDT(i1).sTextOrg
488 w_sTop = sTextDT(i1).sTop
489 w_sBottom = sTextDT(i1).sBottom
490 w_sLeft = sTextDT(i1).sLeft
491 w_sRight = sTextDT(i1).sRight
492 w_iLineNo = sTextDT(i1).iLineNo
493 w_iCenterX = sTextDT(i1).iCenterX
494 w_iCenterY = sTextDT(i1).iCenterY
495
496 sTextDT(i1).sText = sTextDT(i2).sText
497 sTextDT(i1).sTextOrg = sTextDT(i2).sTextOrg
498 sTextDT(i1).sTop = sTextDT(i2).sTop
499 sTextDT(i1).sBottom = sTextDT(i2).sBottom
500 sTextDT(i1).sLeft = sTextDT(i2).sLeft
501 sTextDT(i1).sRight = sTextDT(i2).sRight
502 sTextDT(i1).iLineNo = sTextDT(i2).iLineNo
503 sTextDT(i1).iCenterX = sTextDT(i2).iCenterX
504 sTextDT(i1).iCenterY = sTextDT(i2).iCenterY
505
506 sTextDT(i2).sText = w_sText
507 sTextDT(i2).sTextOrg = w_sTextOrg
508 sTextDT(i2).sTop = w_sTop
509 sTextDT(i2).sBottom = w_sBottom
510 sTextDT(i2).sLeft = w_sLeft
511 sTextDT(i2).sRight = w_sRight
512 sTextDT(i2).iLineNo = w_iLineNo
513 sTextDT(i2).iCenterX = w_iCenterX
514 sTextDT(i2).iCenterY = w_iCenterY
515 End If
516 Next i2
517 Next i1
518 End If
519 End If 'End If (bSortX)
520
521 End Function
522
523 '**************************************************
524 '
525 ' 行データを作成
526 '
527 ' Create : 2023/03/07
528 '
529 '**************************************************
530 Private Function MargTextLine( _
531 ByVal iPageNo As Long, _
532 ByRef sOutData() As PageLineZahyo, _
533 ByRef sTextDT() As TextZahyo) As Boolean
534 MargTextLine = True
535
536 Dim i1 As Long
537 Dim i2 As Long
538
539 '初期化
540 For i1 = 0 To UBound(sOutData(iPageNo).sLineData)
541 sOutData(iPageNo).sLineData(i1) = ""
542 sOutData(iPageNo).iLineDataY(i1) = -1
543 Next i1
544
545 '行番号単位に行テキストを作成
546 For i1 = 0 To UBound(sTextDT)
547 i2 = sTextDT(i1).iLineNo - 1
548 With sOutData(iPageNo)
549 .sLineData(i2) = _
550 .sLineData(i2) & sTextDT(i1).sTextOrg
551 .iLineDataY(i2) = sTextDT(i1).iCenterY
552 End With
553 Next i1
554
555 End Function
556
557 '**************************************************
558 '
559 ' ヘッダー、フッターの判断
560 '
561 ' Create : 2023/03/07
562 ' Update : 2023/03/12
563 '
564 ' ヘッダー、フッターの抽出条件:
565 ' 文字列+連続頁+前後ページでの高さ(Y)が同じ
566 '
567 ' C2_LONG_HD,C2_LONG_FTをTrueにすると行間が長い行は
568 ' 比較対象から外す。(推奨)
569 '
570 '**************************************************
571 Private Function Get_Header_Footer( _
572 ByRef sOutData() As PageLineZahyo) As Boolean
573
574 Get_Header_Footer = True
575
576 Dim iPageNo As Long 'ページ番号
577 Dim iNextPg As Long '次のページ番号
578 Dim i1 As Long
579 Dim i2 As Long
580 Dim iHeaderEnd As Long 'ヘッダー最終処理の位置
581 Dim iFooterEnd As Long 'フッター最終処理の位置
582 Dim iSa As Long '差
583
584 '初期化
585 For iPageNo = 0 To UBound(sOutData)
586 With sOutData(iPageNo)
587 For i1 = 0 To C_MAXLINE
588 .bHeaderFlag(i1) = False
589 .bFooterFlag(i1) = False
590 .bHeaderST(i1) = False 'デバッグ用
591 .bFooterST(i1) = False 'デバッグ用
592 Next i1
593 End With
594 Next iPageNo
595
596 '■ヘッダー、フッター
597 For iPageNo = 0 To UBound(sOutData)
598 If sOutData(iPageNo).iLineCount < 0 Then _
599 GoTo Next_Get_Header_Footer:
600
601 iNextPg = iPageNo + 1
602
603 '▼ヘッダーの編集
604 iHeaderEnd = -1
605 '当ページと次ページとの比較
606 If iPageNo < UBound(sOutData) Then
607 iSa = Round(sOutData(iPageNo).iAveTextY / C_DEV)
608 For i1 = 0 To sOutData(iPageNo).iLineCount - 1
609 If (DeleteText(sOutData(iPageNo).sLineData(i1)) = _
610 DeleteText(sOutData(iNextPg).sLineData(i1))) _
611 And Abs(sOutData(iPageNo).iLineDataY(i1) - _
612 sOutData(iNextPg).iLineDataY(i1)) <= iSa _
613 Then
614 If C2_LONG_HD And (i1 > 0) Then
615 '1行上との行間が大きい時はヘッダーにしない。
616 If Abs(sOutData(iPageNo).iLineDataY(i1 - 1) - _
617 sOutData(iPageNo).iLineDataY(i1)) > _
618 (sOutData(iPageNo).iAveTextY * _
619 C2_LONG_BAI) Then
620 Exit For
621 End If
622 End If
623 sOutData(iPageNo).bHeaderFlag(i1) = True
624 sOutData(iNextPg).bHeaderFlag(i1) = True
625 iHeaderEnd = i1
626 Else
627 Exit For
628 End If
629 Next i1
630 End If
631 For i1 = sOutData(iPageNo).iLineCount - 1 To 0 Step -1
632 If sOutData(iPageNo).bHeaderFlag(i1) Then
633 iHeaderEnd = i1
634 Exit For
635 End If
636 Next i1
637
638 'ヘッダーの真下の近い行はヘッダーとする
639 If C2_SHORT_HD And (iHeaderEnd <> -1) Then
640 '真下の行はヘッダーとして取り込む
641 With sOutData(iPageNo)
642 iSa = .iAveTextY * C2_SHORT_BAI
643 For i2 = (iHeaderEnd + 1) To (.iLineCount - 1)
644 If Abs(.iLineDataY(i2 - 1) - _
645 .iLineDataY(i2)) <= iSa Then
646 .bHeaderFlag(i2) = True
647 .bHeaderST(i2) = True
648 Else
649 Exit For
650 End If
651 Next i2
652 End With
653 End If
654
655 '▼フッターの編集
656 iFooterEnd = -1
657 If iPageNo < UBound(sOutData) Then
658 i2 = sOutData(iNextPg).iLineCount - 1
659 '当ページと次ページとの比較
660 If (i2 >= 0) And (iPageNo < UBound(sOutData)) Then
661 iSa = Round(sOutData(iPageNo).iAveTextY / C_DEV)
662 For i1 = sOutData(iPageNo).iLineCount - 1 To 0 Step -1
663 If i1 <= iHeaderEnd Then Exit For 'ヘッダーに達した
664
665 If (DeleteText(sOutData(iPageNo).sLineData(i1)) = _
666 DeleteText(sOutData(iNextPg).sLineData(i2))) _
667 And Abs(sOutData(iPageNo).iLineDataY(i1) - _
668 sOutData(iNextPg).iLineDataY(i2)) <= iSa _
669 Then
670 sOutData(iPageNo).bFooterFlag(i1) = True
671 sOutData(iNextPg).bFooterFlag(i2) = True
672 iFooterEnd = i1
673 If C2_LONG_FT And (i1 > 0) Then
674 '1行上との行間が大きい時は「次は」比較しない。
675 If Abs(sOutData(iPageNo).iLineDataY(i1 - 1) - _
676 sOutData(iPageNo).iLineDataY(i1)) > _
677 (sOutData(iPageNo).iAveTextY * C2_LONG_BAI) Then
678 Exit For
679 End If
680 End If
681 End If
682 Next i1
683 End If
684 End If
685 For i1 = 0 To sOutData(iPageNo).iLineCount - 1
686 If sOutData(iPageNo).bFooterFlag(i1) Then
687 iFooterEnd = i1
688 Exit For
689 End If
690 Next i1
691 'フッターの真上の近い行はフッターとして取り込む
692 If C2_SHORT_FT And (iFooterEnd <> -1) Then
693 With sOutData(iPageNo)
694 iSa = .iAveTextY * C2_SHORT_BAI
695 For i1 = iFooterEnd To 1 Step -1
696 If Abs(.iLineDataY(i1) - _
697 .iLineDataY(i1 - 1)) <= iSa Then
698 .bFooterFlag(i1 - 1) = True
699 .bFooterST(i1 - 1) = True
700 Else
701 Exit For
702 End If
703 Next i1
704 End With
705 End If
706
707 Next_Get_Header_Footer:
708 Next iPageNo
709
710 '■ヘッダー、フッターの数を数える
711 For iPageNo = 0 To UBound(sOutData)
712 With sOutData(iPageNo)
713 .iHeaderCount = 0
714 For i1 = 0 To C_MAXLINE
715 If .bHeaderFlag(i1) Then
716 .iHeaderCount = .iHeaderCount + 1
717 End If
718 Next i1
719 .iFooterCount = 0
720 For i1 = 0 To C_MAXLINE
721 If .bFooterFlag(i1) Then
722 .iFooterCount = .iFooterCount + 1
723 End If
724 Next i1
725 End With
726 Next iPageNo
727
728 End Function
729
730 '**************************************************
731 '
732 ' ヘッダーとフッターからページ番号と日付に当たる部分を
733 ' 削除する。比較の対象から外すためです。
734 '
735 ' Create : 2023/03/07
736 ' Update : 2023/03/08
737 '
738 ' ※[年月日]を入れれば日付を外して比較が出来る
739 '**************************************************
740 Private Function DeleteText( _
741 ByVal sText As String) As String
742
743 Const D_DATA = "0123456789年月日" & _
744 "#./*-=+!""$%&'()~|`[]{}@*:;<>?_\/,"
745 Dim i1 As Long
746 Dim sW As String
747 Dim iCnt As Long
748
749 '連続する空白は1つにする
750 sText = Replace(sText, " ", " ")
751 sText = Replace(sText, " ", " ")
752
753 For i1 = 1 To Len(D_DATA)
754 sW = Mid$(D_DATA, i1, 1)
755 sText = Replace(sText, sW, "")
756 Next i1
757
758 DeleteText = Trim$(sText)
759
760 End Function
761
762 '**************************************************
763 '
764 ' 処理結果をテキスト出力する。メモ帳も起動する。
765 '
766 ' ※デバッグ用ロジック
767 '
768 ' Create : 2023/03/07
769 ' Update : 2023/03/11
770 '
771 '**************************************************
772 Private Sub WriteLog( _
773 ByVal sInFilePathIn As String, _
774 ByRef sOutData() As PageLineZahyo)
775
776 Dim sLogFilePath As String
777 Dim iFileNo As Long
778 Dim iPageNo As Long
779 Dim i1 As Long
780 Dim i2 As Long
781 Dim iLineC As Long
782 Dim iTextC As Long
783
784 Dim sPage As String
785 Dim iPageL As Long
786 Dim sPrint As String
787 Dim iSeq As Long
788
789 '実行中の当ファイルが格納されたフォルダのパス
790 sLogFilePath = ThisWorkbook.Path & "\" 'Excel
791 iFileNo = FreeFile()
792 sLogFilePath = ThisWorkbook.Path & "\" & "\Log-" & _
793 Format(Date, "yyyy-mmdd-") & _
794 Format(Time, "hhmm-ss") & ".txt"
795 Open sLogFilePath For Append As #iFileNo
796
797 '見出し
798 Print #iFileNo, "Log-File = " & sLogFilePath
799 Print #iFileNo, "IN-PDF = " & sInFilePathIn
800
801 'ヘッダー、フッターの一覧
802 For iPageNo = 0 To UBound(sOutData)
803 With sOutData(iPageNo)
804 sPage = "Page=(" & (iPageNo + 1) & "/" & _
805 (UBound(sOutData) + 1) & ") "
806 iPageL = Len(sPage)
807 'ヘッダー出力
808 iSeq = 1
809 For i2 = 0 To C_MAXLINE
810 If .bHeaderFlag(i2) Then
811 sPrint = sPage & iSeq & _
812 ".Header(" & .sLineData(i2) & ")" & _
813 "Y=" & .iLineDataY(i2)
814 Print #iFileNo, sPrint
815 sPage = Space(iPageL)
816 iSeq = iSeq + 1
817 End If
818 Next i2
819 'フッター出力
820 iSeq = 1
821 For i2 = 0 To C_MAXLINE
822 If .bFooterFlag(i2) Then
823 sPrint = sPage & iSeq & _
824 ".Footer(" & .sLineData(i2) & ")" & _
825 "Y=" & .iLineDataY(i2)
826 Print #iFileNo, sPrint
827 sPage = Space(iPageL)
828 iSeq = iSeq + 1
829 End If
830 Next i2
831 If Trim(sPage) <> "" Then
832 Print #iFileNo, sPage
833 End If
834 End With
835 Next iPageNo
836 Print #iFileNo, vbCrLf & _
837 "***************************" & vbCrLf
838
839 '各ページの作業用値の一覧
840 iLineC = 0: iTextC = 0
841 For iPageNo = 0 To UBound(sOutData)
842 With sOutData(iPageNo)
843 Print #iFileNo, _
844 "Page=(" & (iPageNo + 1) & "/" & _
845 (UBound(sOutData) + 1) & ")" & _
846 " 行数=" & .iLineCount & _
847 " テキスト数=" & .iTextCount & _
848 " テキスト平均Y高さ=" & .iAveTextY & _
849 " ヘッダー数=" & .iHeaderCount & _
850 " フッター数= " & .iFooterCount
851 If (iLineC < .iLineCount) Then iLineC = .iLineCount
852 If (iTextC < .iTextCount) Then iTextC = .iTextCount
853 End With
854 Next iPageNo
855 Print #iFileNo, vbCrLf & " 最大行数=" & _
856 iLineC & " 最大テキスト数=" & iTextC
857 Print #iFileNo, vbCrLf & "***************************"
858
859 '行データ
860 For iPageNo = 0 To UBound(sOutData)
861 Print #iFileNo, vbCrLf & "======================="
862 With sOutData(iPageNo)
863 sPage = "Page=(" & (iPageNo + 1) & "/" & _
864 (UBound(sOutData) + 1) & ") "
865 iPageL = Len(sPage)
866 Print #iFileNo, vbCrLf & sPage & _
867 " テキスト数=" & .iTextCount & _
868 " 行数=" & .iLineCount & _
869 " テキスト平均Y高さ=" & .iAveTextY & _
870 " ヘッダー数=" & .iHeaderCount & _
871 " フッター数= " & .iFooterCount
872 sPage = Space(iPageL)
873 iPageL = Len(sPage)
874
875 'ヘッダー出力
876 iSeq = 1
877 For i2 = 0 To C_MAXLINE
878 If .bHeaderFlag(i2) Then
879 sPrint = sPage & iSeq & _
880 ".Header(" & .sLineData(i2) & ")" & _
881 "Y=" & .iLineDataY(i2) & _
882 IIf(.bHeaderST(i2), " S*", "")
883 Print #iFileNo, sPrint
884 sPage = Space(iPageL)
885 iSeq = iSeq + 1
886 End If
887 Next i2
888
889 'フッター出力
890 iSeq = 1
891 For i2 = 0 To C_MAXLINE
892 If .bFooterFlag(i2) Then
893 sPrint = sPage & iSeq & _
894 ".Footer(" & .sLineData(i2) & ")" & _
895 "Y=" & .iLineDataY(i2) & _
896 IIf(.bFooterST(i2), " S*", "")
897 Print #iFileNo, sPrint
898 sPage = Space(iPageL)
899 iSeq = iSeq + 1
900 End If
901 Next i2
902 Print #iFileNo, ""
903
904 'テキスト行
905 For i2 = 0 To .iLineCount - 1
906 Print #iFileNo, "p" & (iPageNo + 1) & " " & _
907 (i2 + 1) & "/" & .iLineCount & _
908 " Text=(" & .sLineData(i2) & ")" & _
909 "Y=" & .iLineDataY(i2)
910 Next i2
911 End With
912 Next iPageNo
913 Print #iFileNo, vbCrLf & "*** EOF ***"
914 Close #iFileNo
915
916 'メモ帳を起動
917 Dim ReturnValue
918 ReturnValue = Shell("NOTEPAD.EXE " & sLogFilePath, 1)
919 End Sub
テキストの並び替え関連の定数
テキストをY座標をもとに並び替えます。したくない時は C1_SORTY をFlaseに変更します。行単位(=座標Yが同じ)でテキストのX座標で並び替えます。したくない時は C1_SORTX をFlaseに変更します。Y座標での並び替えを行うときに、同時にY座標の微妙な誤差(Private Const C1_SA As Long = 3)以内ならば同じ行の先頭のテキストのY座標値に強制的に変更しています。変更したくない時は C1_Y_FIX をFalseに変更します。
Private Const C1_Y_FIX As Boolean = True 'Y座標の修正
Private Const C1_SA As Long = 3 '★差の範囲 Y座標
Private Const C1_SORTX As Boolean = True 'X軸ソートの実行
Private Const C1_SORTY As Boolean = True 'Y軸ソートの実行
ヘッダー、フッター関連の定数
ヘッダーと判断した行の真下(直下)にある行もヘッダーと見なします。したくない場合は以下の C2_SHORT_HD 定数をFalseに変更します。フッターも同様です。フッター行の真上(直上)ある行もヘッダーと見なします。したくない場合はC2_SHORT_FT 定数をFalseにします。
C2_SHORT_BAI 定数は真下、真上と判断する時の計算倍率です。テキストの高さの平均値にこの倍率を掛けて、計算します。この値を大きくすると真下、真上と判断する行が増えます。大きすぎると本文の内容を拾ってしまいます。計算の詳細はVBAソースを御覧ください。
Private Const C2_SHORT_HD As Boolean = True 'ヘッダーの真下
Private Const C2_SHORT_FT As Boolean = True 'フッターの真上
Private Const C2_SHORT_BAI = 1.3 '★行(高さ)の倍率
ヘッダーと判断した行、又はフッターと判断した行と一定以上に離れているテキストは、ヘッダー、又はフッターの判断はしない方がイイです。以下の定数でTrueを設定すると、これが機能します。離れていても判断(チェック)して欲しい時はFalseにします。デフォルトはFalseで、離れていてもヘッダー、フッターの判断をします。
C2_LONG_BAI 定数は離れる行数の最大倍率(2.5行)です。この値を大きくするとチェック対象の行が増えます。
'行間が長い行はチェック対象から外す。
'True:外す False:外さない
Private Const C2_LONG_HD As Boolean = False 'ヘッダー
Private Const C2_LONG_FT As Boolean = False 'フッター
Private Const C2_LONG_BAI = 2.5 '★行(高さ)の倍率
上記のC2_SHORT_BAI 定数とC2_LONG_BAI 定数は非常に重要です。抽出漏れが有ると感じた時は迷わず値を大きくして見て下さい。
その他の定数
1ページの行数の最大は200(0~200)です。C_MAXLINEで指定してます。行の判断の計算値の分母はC_DEVで4をデフォルトにしています。
Private Const C_MAXLINE As Long = 200 'ページ中の最大行数
Private Const C_DEV As Long = 4 '差計算時の分母
当関数の評価手順
当関数付属の出力テキストファイルでフッターとヘッダーの判断結果を確認します。できるだけ種類の異なるPDFを数種類用意します。
- 最初は入力PDFを指定するだけで、定数は全てデフォルトにします。
- 次に以下の定数のTrueをFalseに、FalseをTrueに変更して再実行します。
Private Const C2_SHORT_HD As Boolean = True
Private Const C2_SHORT_FT As Boolean = True
Private Const C2_LONG_HD As Boolean = False
Private Const C2_LONG_FT As Boolean = False
- 定数をもとに戻し、以下の値を少しずつ大きくしてみます。
Private Const C2_SHORT_BAI = 1.3
Private Const C2_LONG_BAI = 2.5
C2_LONG_BAI定数はC2_LONG_HDとC2_LONG_FT をTrueにしないと確認できません。
- 時間があれば、今度は値を小さくしてみます。
出力したテキストファイルはWinMerge 日本語版等でテキスト比較を行うと簡単に違いを確認できます。
備考
下記は処理結果をテキストファイルへ出力する確認用のロジックです。メモ帳も起動します。必要なくなったら、WriteLog 処理も削除して下さい。
Call WriteLog(sInFilePathIn, sOutData)
ヘッダー、フッターに関する情報が不要の方は、OutSquareRects関数内に有る以下の部分を削除して下さい。少しは処理速度が上がります。
bRet = Get_Header_Footer(sOutData)
参照
その他
- 関数内部にはデバッグ用のロジックも一部残してあります。
サイト管理者の技術メモ
これ以降はサイト管理者が当ページを管理するための技術メモです。公開用には書いていません。よって、見る必要は無いです。
関数内の数値「-1」の扱い
デバッグ時に使います。未処理だと実行エラーを発生されるようにしています。また、データが存在しなかった時の判断にも利用しています。
「Microsoft Print to PDF」と「Adobe PDF」との違い
MS Office に入っている文書をPDFにする「Microsoft Print to PDF」とAdobe Acrobatに付いている「Adobe PDF」との違いが当関数のテストで分かった。
「Microsoft Print to PDF」で作ったPDFは同じ行でもテキストの座標Yが異なるケースがかなり有る。Y座標値「2」程度だが、当関数でこれを処理すると別の行になってしまう。「Adobe PDF」で作成したPDFは元の文書が同じ行ならば座標Yは同じになる。画面表示するPDF上のテキストは同じ箇所に有るように見えるが、これをプログラムで扱うとなると別の行の文字列になってしまうのは困る。中心座標Y値が「2」しか違わないのを修正する「座標Y誤差自動修正機能」なるものを追加する。
Y座標誤差自動修正機能
「座標Y軸ソート」をしたときに、直前・直後テキストの前後のY座標の差が有り、その差が2以内の場合は、直前のY座標の値を直後のテキストのY座標に修正する。これが発生した時は再度「座標Y軸ソート」を行う必要が有る。 <ー勘違いしてました。再ソートは不要でした。
Y軸ソート時の中心座標Yでの強制修正:Sort_TextData関数内
同じ行の判断は中心座標Yでソートした後にC_DEVの定数を使って判断している。このソートを行うと座標Yの値によってはテキストが行内の本来の場所とは異なる場所(前後)に入ってしまうケースが出ている。それをカバーする為にソート後に「座標Y誤差の自動修正」ロジックを追加した。座標Yの差が2以下ならば前のテキストの座標Yを直後のテキストの座標Yにセットする。
この後にテキストから行データを作成する処理(関数:MargTextLine)で、前後のテキストの座標Y値がテキストの平均高さの1/4かの判断を行っている。同一行の判断のために。コレはコレで必要な処理、と思う。
微妙な誤差は強制修正が必要だが、ある程度の差は通常の計算値として通常に使用する必要が有る。上記はそうゆう話。
使えない画像
せっかく作ったのに、どこの文章にも使えない画像。
以上。