TOP > サンプル/関数 > 関数:PDFを特定のフォーマットに変換する [...]
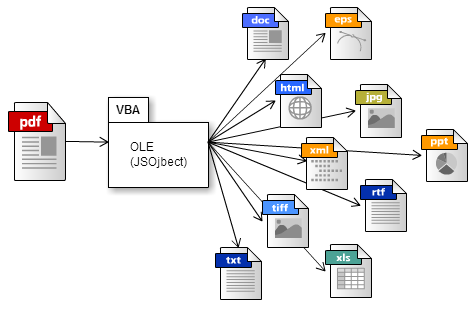
機能
PDFファイルを特定のフォーマット(doc , html , xml 等) に変換する。
- 変換可能な別フォーマットの種類はインストールされている Acrobat Pro アプリのバージョンによっても異なる。
テキスト(txt) , Word(doc) , Word97(doc) , Word07(docx) , EPS , HTML , HTML 3.2形式 , HTML 4形式 , JPEG2K(jpf, jpx, jp2, j2k, j2c, jpc) , JPEG(jpeg , jpg , jpe) , TEXT(txt) , PNG , PowerPoint(pptx) , spreadsheet , PS , rtf , Excel(xlsx) , tiff(tiff , tif) , XML , PDF/A , PDF/E , PDF/X
詳細は ExportTask.xml 参照 - 出力先フォルダを指定できる ※一括
- PDFファイル単位で出力時のファイル名が指定できる
- 当関数は変換する前に厳重なPDFのファイル状態と動作環境の状態を事前にチェックする
形式
[boolean] = Convert_PDF_Format_Main_nnn2(
string strConvertPdf() ,
string strOutputFolder )
引数
引数の説明は難しいので、必ずサンプルも参照してください。
- 第1引数 ( string strConvertPdf() ) : ※備考も参照
2次元配列。 以下は2次元目の位置
0 : 変換元のPDFのフルパス (IN/必須)
1 : 変換タイプ (IN/必須)
例:accesstext , doc , pdfx
2 : 変換先ファイル名 (IN/任意)
未指定時はPDFファイルのファイル名+変換タイプのデフォルト拡張子
3 : 処理結果 エラーメッセージをセット(OUT) - 第2引数 ( string strOutputFolder ) : (IN)
変換先のフォルダ名
既に存在する必要が有る。無いとエラーになる。
戻り値
- True : 正常な処理
- False : 実行エラー等
動作するバージョン
| Version | Adobe Acrobat |
備考
|
|---|---|---|
|
4
|
NO
| Acrobat 4.0 ※Windows 98SE + Excel 2000 |
|
5
|
NO
| Acrobat 5.0.5 |
|
6
|
NO
| Acrobat 6.0.3 Pro |
|
7
|
NO
| Acrobat 7.1.4 Pro |
|
8
|
OK
| Acrobat 8.2.2 Pro |
|
9
|
-
| Acrobat 9.3.2 Extended |
|
10
|
-
| Acrobat X (10.1.8) Extended |
|
11
|
-
| Acrobat XI (11.0.04) Extended |
未確認だが Acrobat 8 Pro 以上で動作すると説明では有る。
|
Microsoft
Excel
|
結果
|
備考
|
|---|---|---|
|
2000
|
NO
| ※OS : Windows 98SE |
|
XP
|
-
| ※Office XP [=2002] |
|
2003
|
-
| Windows XP Pro (SP3) |
|
2007
|
OK
| Windows 7 64bit Home (SP1) |
|
2010
|
-
|
- OK : 正常処理する。
- NO : 正常に処理できない。
- - : 未確認。
VBAサンプル
- 参照設定を事前に行う。
- 以下のサンプルはテスト用です。
F8キーでステップ実行して動作確認できます。
Download:sample-ConvertPDFFormat.xls
001 Option Explicit
002
003
004 ' 関数のテスト用 スクリプト
005 ' http://pdf-file.nnn2.com/?p=768
006
007
008 ' 関数のテスト用 スクリプト
009
010 Sub Convert_PDF_Format_Main_TEST()
011
012 Dim bRet As Boolean
013 Dim strOutputFolder As String
014 Dim strConvPDFfile(2, 3) As String
015 Dim i As Long
016
017 strOutputFolder = "I:¥Adobe PDF¥Output"
018
019 strConvPDFfile(0, 0) = "I:¥Adobe PDF¥TEST-NO-Sec.pdf"
020 strConvPDFfile(0, 1) = "accesstext" '変換タイプ
021 strConvPDFfile(0, 2) = "TEST-NO-Sec.txt" '出力ファイル名
022 strConvPDFfile(0, 3) = "" '処理結果
023 strConvPDFfile(1, 0) = "I:¥Adobe PDF¥TEST-NO-Sec.pdf"
024 strConvPDFfile(1, 1) = "doc" '変換タイプ
025 strConvPDFfile(1, 2) = "TEST-NO-Sec.doc" '出力ファイル名
026 strConvPDFfile(1, 3) = "" '処理結果
027 strConvPDFfile(2, 0) = "I:¥Adobe PDF¥VBJavaScript.pdf"
028 strConvPDFfile(2, 1) = "eps" '変換タイプ
029 strConvPDFfile(2, 2) = "" '未指定はVBJavaScript.epsになる
030 strConvPDFfile(2, 3) = "" '処理結果
031
032 bRet = Convert_PDF_Format_Main_nnn2(strConvPDFfile, strOutputFolder)
033
034 For i = LBound(strConvPDFfile, 1) To UBound(strConvPDFfile)
035 If strConvPDFfile(i, 3) <> "" Then
036 Debug.Print i & " " & strConvPDFfile(i, 0)
037 Debug.Print strConvPDFfile(i, 3)
038 End If
039 Next i
040
041 End Sub
042
043 '********************************************************
044 '
045 ' PDFを別フォーマット形式に変換します(Main)
046 '
047 ' ・変換できる環境であるか事前チェックします
048 ' ・インストールされているAcrobatに合った変換IDテーブルを作成
049 ' ・出力先フォルダが指定できる
050 ' ・出力ファイル名が指定できる
051 '
052 ' Create : 2013/10/09
053 ' Update :
054 ' Vertion : 1.0.1
055 '
056 ' 引数1 : strConvertPdf() As String (IN/OUT)
057 ' ※2次元配列で以下は2次元目の位置
058 ' 0 : 変換元のPDFのフルパス (IN/必須)
059 ' 1 : 変換タイプ (IN/必須)
060 ' 例:accesstext , doc , pdfx
061 ' 2 : 変換先ファイル名 (IN/任意)
062 ' 3 : 処理結果 エラーメッセージをセット(OUT)
063 '
064 ' 引数2 : strOutputFolder As String (IN)
065 ' 出力先フォルダ名
066 '
067 ' 戻り値 : True 正常終了
068 ' False エラーが有る
069 '
070 ' 環境条件:
071 ' Acrobat 8 Pro,9 Pro,10 Pro ,11 Pro が
072 ' 動作環境にインストールされている必要がある。
073 '
074 ' 備考 :・既にファイルが存在しても無条件に上書きされる
075 ' ・PDFファイルを処理はサイレントで行われる
076 ' URL : http://pdf-file.nnn2.com/?p=768
077 ' その他 : 著作権等は主張しません。
078 ' 上記URLにコメントを頂けると嬉しいです。
079 '
080 ' 1.0.1 : Acrobat 2017対応
081 '
082 '********************************************************
083
084 Public Function Convert_PDF_Format_Main_nnn2( _
085 ByRef strConvertPdf() As String, _
086 ByVal strOutputFolder As String) As Boolean
087
088 On Error GoTo Err_Convert_PDF_Format_Main_nnn2:
089
090 Dim tblCovertPara(19, 2) As String '変換パラメータ・テーブル
091 Dim strAcrobatVersion As String 'Acrobatバージョン
092 Dim strAcrobatPath As String 'File full path
093 Dim strMsg As String 'Error Message
094 Dim bRet As Boolean '戻り値
095
096 Dim i As Long
097 Dim j As Long
098 Dim lIndex As Long
099 Dim strPara As String
100 Dim lPara_Inx As Long
101 Dim strOutputFile As String
102 Dim strOutFileName As String
103
104 Const CON_APP = "Acrobat" 'Acrobat
105
106 Convert_PDF_Format_Main_nnn2 = True
107
108 '----------------------------------------
109 'Acrobat バージョンの取得
110 bRet = Get_Adobe_App_Info_nnn2( _
111 CON_APP, _
112 strAcrobatPath, _
113 strAcrobatVersion, _
114 strMsg)
115 If bRet = False Then
116 Convert_PDF_Format_Main_nnn2 = False
117 MsgBox "01:Acrobat バージョンの取得 エラー / " & strMsg
118 Exit Function
119 End If
120 If strAcrobatVersion = vbNullString Then Exit Function
121
122 '----------------------------------------
123 'PDFの変換テーブルの作成
124 bRet = Convert_PDF_Format_ET_nnn2(strAcrobatVersion, tblCovertPara)
125 If bRet = False Then
126 Convert_PDF_Format_Main_nnn2 = False
127 Exit Function
128 End If
129
130 '----------------------------------------
131 '出力先フォルダの存在チェック
132 If strOutputFolder = "" Then
133 Convert_PDF_Format_Main_nnn2 = False
134 MsgBox "02:出力先フォルダを指定して下さい"
135 Exit Function
136 End If
137 If Right$(strOutputFolder, 1) = "¥" Then
138 strOutputFolder = Left$(strOutputFolder, Len(strOutputFolder) - 1)
139 End If
140 '※Dir関数はフォルダ名の最後に¥が入ってるとエラーになる
141 If Dir$(strOutputFolder, vbDirectory) = "" Then
142 Convert_PDF_Format_Main_nnn2 = False
143 MsgBox "03:出力先フォルダが存在しない"
144 Exit Function
145 End If
146 strOutputFolder = strOutputFolder & "¥"
147
148
149 '----------------------------------------
150 '出力先フォルダのCドライブ以外のチェック
151 '※「Safe Path」についての注意事項
152 '※ http://pdf-file.nnn2.com/?p=229
153 If Left$(strOutputFolder, 1) = "C" Or Left$(strOutputFolder, 1) = "c" Then
154 Convert_PDF_Format_Main_nnn2 = False
155 MsgBox "03:出力先フォルダにCドライブは使えない"
156 Exit Function
157 End If
158
159 '----------------------------------------
160 'ループ処理
161
162 For i = LBound(strConvertPdf, 1) To UBound(strConvertPdf, 1)
163
164 '----------------------------------------
165 'PDFファイルの完全チェック
166 bRet = Check_PDF_W_nnn2(strConvertPdf(i, 0), strMsg)
167 If bRet = False Then
168 strConvertPdf(i, 3) = "10:PDFファイルでは無い / " & strMsg
169 Convert_PDF_Format_Main_nnn2 = False
170 GoTo Skip_Convert_PDF_Format_Main_nnn2:
171 End If
172
173 '----------------------------------------
174 '変換パラメータのチェック
175 strPara = strConvertPdf(i, 1)
176 lPara_Inx = -1
177 For j = LBound(tblCovertPara, 1) To UBound(tblCovertPara, 1)
178 If tblCovertPara(j, 2) = strPara Then
179 lPara_Inx = j
180 Exit For
181 End If
182 Next j
183 If lPara_Inx = -1 Then
184 strConvertPdf(i, 3) = "11:変換パラメータが間違ってる"
185 Convert_PDF_Format_Main_nnn2 = False
186 GoTo Skip_Convert_PDF_Format_Main_nnn2:
187 End If
188
189 '----------------------------------------
190 '出力ファイル名を決定
191 strOutputFile = strConvertPdf(i, 2)
192 If strOutputFile = "" Then
193 '出力ファイル名が指定されて無いので
194 '入力ファイル名を使う
195 strOutFileName = Right$(strConvertPdf(i, 0), _
196 (Len(strConvertPdf(i, 0)) - InStrRev(strConvertPdf(i, 0), "¥")))
197 '拡張子はデフォルトに変更する
198 strOutputFile = strOutputFolder & _
199 Left$(strOutFileName, Len(strOutFileName) - 3) & tblCovertPara(lPara_Inx, 1)
200 Else
201 '出力ファイル名が指定されてる
202 '出力ファイル名に拡張子が存在するかチェック
203 If InStrRev(strOutputFile, ".") < 1 Then
204 '拡張子が指定されてない Not File extension
205 strConvertPdf(i, 3) = "12:出力ファイル名に拡張子が指定されて無い"
206 Convert_PDF_Format_Main_nnn2 = False
207 GoTo Skip_Convert_PDF_Format_Main_nnn2:
208 End If
209 strOutputFile = strOutputFolder & strOutputFile
210
211 End If
212
213 '----------------------------------------
214 '[ページの抽出]等が可能かを事前チェック
215 bRet = Convert_PDF_Format_Check_nnn2(strConvertPdf(i, 0), strMsg)
216 If bRet = False Then
217 '[開くときのパスワード]か
218 '[ページの抽出]が不可のセキュリティ
219 'が有り、PDFを変換できない。
220 strConvertPdf(i, 3) = "13:文書のセキュリティで処理不可 / " & strMsg
221 Convert_PDF_Format_Main_nnn2 = False
222 GoTo Skip_Convert_PDF_Format_Main_nnn2:
223 End If
224
225 '----------------------------------------
226 '変換処理を開始する
227 bRet = Convert_PDF_Format_nnn2(strConvertPdf(i, 0), strOutputFile, _
228 tblCovertPara(lPara_Inx, 0), strMsg)
229 If bRet = False Then
230 strConvertPdf(i, 3) = "14:文書の変換で失敗しました / " & strMsg
231 Convert_PDF_Format_Main_nnn2 = False
232 End If
233
234 Skip_Convert_PDF_Format_Main_nnn2:
235
236 ' If strConvertPdf(i, 3) <> "" Then
237 ' Debug.Print i & ": " & strConvertPdf(i, 3)
238 ' End If
239 Next i
240
241 '----------------------------------------
242 '終了処理
243 ' Debug.Print Time & " End"
244
245 If Convert_PDF_Format_Main_nnn2 = False Then
246 MsgBox "結果に問題を表示しました" & vbCrLf _
247 & "中断した処理もあります" & vbCrLf & _
248 "確認して再度実行して下さい", , "エラー"
249 Else
250 MsgBox "処理は完了しました", , "お知らせ"
251 End If
252
253 Convert_PDF_Format_Main_nnn2 = True
254
255 Exit Function
256
257 Err_Convert_PDF_Format_Main_nnn2:
258 MsgBox "Run time error" & vbCrLf & Err.Number & vbCrLf & _
259 Err.Description, vbApplicationModal, _
260 "実行エラー Convert_PDF_Format_Main_nnn2"
261
262 Convert_PDF_Format_Main_nnn2 = False
263 End Function
264
265
266 '********************************************************
267 '
268 '[ページの抽出]等が可能かを事前チェック
269 '
270 ' Create : 2013/10/09
271 ' Update :
272 ' Vertion : 1.0.0
273 '
274 '********************************************************
275
276 Private Function Convert_PDF_Format_Check_nnn2( _
277 ByRef strCovertPdfFile As String, _
278 ByRef strMessage As String) As Boolean
279
280 On Error GoTo Err_Convert_PDF_Format_Check_nnn2:
281
282 Dim objAcroPDDoc As New Acrobat.AcroPDDoc
283 Dim objAcroPDDocNew As New Acrobat.AcroPDDoc
284 Dim lRet As Long
285 Dim i As Long
286
287 Convert_PDF_Format_Check_nnn2 = True
288 strMessage = ""
289
290 'PDFファイルをサイレントで開く。
291 lRet = objAcroPDDoc.Open(strCovertPdfFile)
292
293 '--------------------------------------------------
294 '「文書を開くときのパスワード」付きPDF
295 If lRet = 0 Then
296 '「文書を開くときのパスワード」付きPDFファイルです。
297 strMessage = "[文書を開くときのパスワード]付きPDFファイル"
298 Convert_PDF_Format_Check_nnn2 = False
299 'コレ以上の処理は出来ない
300 GoTo Skip_Convert_PDF_Format_Check_nnn2:
301 End If
302
303 '--------------------------------------------------
304 '.内容のコピー:内容の選択/コピーの可否
305 '※検討中
306
307 '--------------------------------------------------
308 '.ページの抽出:ページの抽出可否
309 '空の仮のPDFファイルを作成する
310 lRet = objAcroPDDocNew.Create()
311 '仮のPDFファイルに先頭ページを追加する
312 lRet = objAcroPDDocNew.InsertPages(-1, objAcroPDDoc, 0, 1, True)
313 If lRet = 0 Then
314 '「ページの抽出」を許さないPDFファイル
315 strMessage = "[ページの抽出]を許さないPDFファイル"
316 Convert_PDF_Format_Check_nnn2 = False
317 End If
318 'PDFファイルを閉じる ※変更は無視
319 lRet = objAcroPDDoc.Close
320
321 Skip_Convert_PDF_Format_Check_nnn2:
322
323 'オブジェクトを強制開放する
324 Set objAcroPDDoc = Nothing
325 Set objAcroPDDocNew = Nothing
326
327 Exit Function
328
329 Err_Convert_PDF_Format_Check_nnn2:
330 strMessage = Err.Number & " " & Err.Description
331 Convert_PDF_Format_Check_nnn2 = False
332 End Function
333
334
335 '********************************************************
336 '
337 ' PDFを別フォーマット形式に変換する
338 ' Convert to (format) a separate file PDF
339 '
340 ' ※既にファイルが存在しても無条件に上書きされる。
341 '
342 ' Create : 2013/10/09
343 ' Update :
344 ' Vertion : 1.0.0
345 '
346 ' 引数1 : strPdfFilePath As String (IN)
347 ' PDFファイルのフルパス
348 ' 引数2 : strOutputFile As String (IN)
349 ' 変換する出力ファイルのフルパス
350 ' 引数3 : strCmd As String (IN)
351 ' 変換ID
352 ' 引数4 : strMsg As String (OUT)
353 ' エラー発生時のエラーメッセージ
354 ' ""はエラー無し
355 '
356 ' 戻り値 : True 正常処理
357 ' False エラー処理 PDFで無い
358 '
359 ' 備考 : JavaScriptオブジェクト(JavaScript API)を使って
360 ' PDFファイルを別の形式のファイルへ変換する。
361 ' 処理の最初に objAcroApp.CloseAllDocs を実行して
362 ' OLE処理でのエラーが出ない様にする。(経験上より)
363 ' URL : http://pdf-file.nnn2.com/?p=768
364 ' その他 : 著作権等は主張しません。
365 ' 上記URLにコメントを頂けると嬉しいです。
366 '
367 '********************************************************
368
369 Private Function Convert_PDF_Format_nnn2( _
370 ByVal strPdfFilePath As String, _
371 ByVal strOutputFile As String, _
372 ByVal strCmd As String, _
373 ByRef strMsg As String) As Boolean
374
375 On Error GoTo Err_Convert_PDF_Format_nnn2:
376
377 Convert_PDF_Format_nnn2 = True
378
379 Dim objAcroApp As New Acrobat.AcroApp
380 Dim objAcroPDDoc As New Acrobat.AcroPDDoc
381 Dim jso As Object
382 Dim lRet As Long
383
384 '(経験上より)Acrobatアプリをメモリに強制ロードする
385 '※jsoオブジェクトの作成時にエラーとなる場合の回避策
386 lRet = objAcroApp.CloseAllDocs
387 'lRetの結果は見ない
388
389 'Debug
390 ' Debug.Print Time & " SaveAs " & strOutputFile & " , " & strCmd
391
392 lRet = objAcroPDDoc.Open(strPdfFilePath)
393 If lRet = 0 Then
394 Convert_PDF_Format_nnn2 = False
395 strMsg = "20:objAcroPDDoc.Open(" & strPdfFilePath & ")"
396 ' Debug.Print strMsg
397 GoTo Err_Convert_PDF_Format_nnn2:
398 End If
399
400 'JavaScriptオブジェクトを作成する。
401 Set jso = objAcroPDDoc.GetJSObject
402 If jso Is Nothing Then
403 Convert_PDF_Format_nnn2 = False
404 strMsg = "21:not get jso object (Nothing)"
405 ' Debug.Print strMsg
406 GoTo Err_Convert_PDF_Format_nnn2:
407 End If
408
409 'PDFを別ファイルへ変換する
410 jso.SaveAs strOutputFile, strCmd
411 '当関数は上記でエラーが極力出ないように作成済み
412
413 'PDFを閉じる
414 lRet = objAcroPDDoc.Close
415 'lRetの結果は見ない
416
417 'Acrobatアプリケーションを終了する
418 lRet = objAcroApp.Hide
419 lRet = objAcroApp.Exit
420 'オブジェクトを強制開放する
421 Set jso = Nothing
422 Set objAcroPDDoc = Nothing
423 Set objAcroApp = Nothing
424
425 Convert_PDF_Format_nnn2 = True
426 Exit Function
427
428 Err_Convert_PDF_Format_nnn2:
429
430 strMsg = Err.Number & ":" & Err.Description
431 ' Debug.Print strMsg
432 MsgBox strMsg, , "Convert_PDF_Format_nnn2"
433
434 On Error Resume Next
435
436 'Acrobatアプリケーションを終了する
437 lRet = objAcroApp.Hide
438 lRet = objAcroApp.Exit
439 'オブジェクトを強制開放する
440 Set jso = Nothing
441 Set objAcroPDDoc = Nothing
442 Set objAcroApp = Nothing
443 Convert_PDF_Format_nnn2 = False
444 End Function
445
446
447 '********************************************************
448 '
449 ' PDFを別フォーマット形式に変換する(変換ID)テーブルの作成
450 '
451 ' Create : 2013/10/08
452 ' Update : 2017/07/06
453 ' Vertion : 1.0.1
454 '
455 ' 備考:
456 ' ・変換ID:
457 ' PDFを別フォーマットに変換するjsoオブジェクトの
458 ' 変換パラメータ。
459 ' ・デフォルトの拡張子:
460 ' 出力ファイルを指定しなかった時のデフォルトの拡張子。
461 ' ・当処理では On Error 処理は行わない。
462 ' ・"com.adobe.acrobat.xml-1-00" などは「変換ID」と言う。
463 '
464 ' URL : http://pdf-file.nnn2.com/?p=768
465 ' その他 : 著作権等は主張しません。
466 ' 上記URLにコメントを頂けると嬉しいです。
467 ' 1.0.1 : Acrobat 2017対応ロジックの修正
468 '
469 '********************************************************
470
471 Private Function Convert_PDF_Format_ET_nnn2( _
472 ByVal strAcrobatVersion As String, _
473 ByRef tblCovertPara() As String) As Boolean
474
475 '事前チェック
476 If Not (CLng(strAcrobatVersion) >= 8 And CLng(strAcrobatVersion) <= 17) Then
477 MsgBox "Adobe Application バージョンが無い" & _
478 vbCrLf & "又は処理未対応のバージョン", , "実行エラー"
479 Convert_PDF_Format_ET_nnn2 = False
480 Exit Function
481 End If
482
483 Dim i As Long
484 Dim j As Long
485 Dim strPara() As String '作業用
486
487 'Initialization
488 For i = LBound(tblCovertPara, 1) To UBound(tblCovertPara, 1)
489 For j = LBound(tblCovertPara, 2) To UBound(tblCovertPara, 2)
490 tblCovertPara(i, j) = vbNullString
491 Next j
492 Next i
493
494 'Value of the array table
495 'Acrobatバージョン単位にExportTask.xmlの情報を元に
496 '変換テーブルを作成する
497
498 Select Case strAcrobatVersion
499
500 Case "8"
501 'Acrobat 8 ExportTask.xml
502
503
504 tblCovertPara(0, 0) = "com.adobe.acrobat.accesstext" '変換ID
505 tblCovertPara(0, 1) = "txt" '出力時のデフォルト拡張子
506
507 tblCovertPara(1, 0) = "com.adobe.acrobat.doc"
508 tblCovertPara(1, 1) = "doc"
509
510 tblCovertPara(2, 0) = "com.adobe.acrobat.eps"
511 tblCovertPara(2, 1) = "eps"
512 tblCovertPara(3, 0) = "com.adobe.acrobat.html-3-20"
513 tblCovertPara(3, 1) = "html"
514 tblCovertPara(4, 0) = "com.adobe.acrobat.html-4-01-css-1-00"
515 tblCovertPara(4, 1) = "html"
516 tblCovertPara(5, 0) = "com.adobe.acrobat.jp2k"
517 tblCovertPara(5, 1) = "j2k"
518 tblCovertPara(6, 0) = "com.adobe.acrobat.jpeg"
519 tblCovertPara(6, 1) = "jpeg"
520 tblCovertPara(7, 0) = "com.adobe.acrobat.plain-text"
521 tblCovertPara(7, 1) = "txt"
522 tblCovertPara(8, 0) = "com.adobe.acrobat.png"
523 tblCovertPara(8, 1) = "png"
524 tblCovertPara(9, 0) = "com.adobe.acrobat.ps"
525 tblCovertPara(9, 1) = "ps"
526 tblCovertPara(10, 0) = "com.adobe.acrobat.rtf"
527 tblCovertPara(10, 1) = "rtf"
528 tblCovertPara(11, 0) = "com.adobe.acrobat.svgxpdf"
529 tblCovertPara(11, 1) = "svgx" '"pdf"も1001エラー
530 tblCovertPara(12, 0) = "com.adobe.acrobat.tiff"
531 tblCovertPara(12, 1) = "tiff"
532 tblCovertPara(13, 0) = "com.adobe.acrobat.xml-1-00"
533 tblCovertPara(13, 1) = "xml"
534 tblCovertPara(14, 0) = "com.adobe.acrobat.xpdf"
535 tblCovertPara(14, 1) = "pdf"
536 tblCovertPara(15, 0) = "com.callas.preflight.pdfa"
537 tblCovertPara(15, 1) = "pdf"
538 tblCovertPara(16, 0) = "com.callas.preflight.pdfx"
539 tblCovertPara(16, 1) = "pdf"
540
541 Case "9"
542 'Acrobat 9 ExportTask.xml
543
544 '変換ID
545 tblCovertPara(0, 0) = "com.adobe.acrobat.accesstext"
546 '出力時のデフォルト拡張子
547 tblCovertPara(0, 1) = "txt"
548 tblCovertPara(1, 0) = "com.adobe.acrobat.doc"
549 tblCovertPara(1, 1) = "doc"
550 tblCovertPara(2, 0) = "com.adobe.acrobat.eps"
551 tblCovertPara(2, 1) = "eps"
552 tblCovertPara(3, 0) = "com.adobe.acrobat.html-3-20"
553 tblCovertPara(3, 1) = "html"
554 tblCovertPara(4, 0) = "com.adobe.acrobat.html-4-01-css-1-00"
555 tblCovertPara(4, 1) = "html"
556 tblCovertPara(5, 0) = "com.adobe.acrobat.jp2k"
557 tblCovertPara(5, 1) = "j2k"
558 tblCovertPara(6, 0) = "com.adobe.acrobat.jpeg"
559 tblCovertPara(6, 1) = "jpeg"
560 tblCovertPara(7, 0) = "com.adobe.acrobat.plain-text"
561 tblCovertPara(7, 1) = "txt"
562 tblCovertPara(8, 0) = "com.adobe.acrobat.png"
563 tblCovertPara(8, 1) = "png"
564 tblCovertPara(9, 0) = "com.adobe.acrobat.ps"
565 tblCovertPara(9, 1) = "ps"
566 tblCovertPara(10, 0) = "com.adobe.acrobat.rtf"
567 tblCovertPara(10, 1) = "rtf"
568 tblCovertPara(11, 0) = "com.adobe.acrobat.svgxpdf"
569 tblCovertPara(11, 1) = "svgx"
570 tblCovertPara(12, 0) = "com.adobe.acrobat.tiff"
571 tblCovertPara(12, 1) = "tiff"
572 tblCovertPara(13, 0) = "com.adobe.acrobat.xml-1-00"
573 tblCovertPara(13, 1) = "xml"
574 tblCovertPara(14, 0) = "com.adobe.acrobat.xpdf"
575 tblCovertPara(14, 1) = "xpdf"
576 tblCovertPara(15, 0) = "com.callas.preflight.pdfa"
577 tblCovertPara(15, 1) = "pdf"
578 tblCovertPara(16, 0) = "com.callas.preflight.pdfe"
579 tblCovertPara(16, 1) = "pdf"
580 tblCovertPara(17, 0) = "com.callas.preflight.pdfx"
581 tblCovertPara(17, 1) = "pdf"
582
583 Case "10"
584 'Acrobat X (10.0) ExportTask.xml
585
586 '変換ID
587 tblCovertPara(0, 0) = "com.adobe.acrobat.accesstext"
588 '出力時のデフォルト拡張子
589 tblCovertPara(0, 1) = "txt"
590 tblCovertPara(1, 0) = "com.adobe.acrobat.doc"
591 tblCovertPara(1, 1) = "doc"
592 tblCovertPara(2, 0) = "com.adobe.acrobat.docx"
593 tblCovertPara(2, 1) = "docx"
594 tblCovertPara(3, 0) = "com.adobe.acrobat.eps"
595 tblCovertPara(3, 1) = "eps"
596 tblCovertPara(4, 0) = "com.adobe.acrobat.html"
597 tblCovertPara(4, 1) = "html"
598 tblCovertPara(5, 0) = "com.adobe.acrobat.jp2k"
599 tblCovertPara(5, 1) = "j2k"
600 tblCovertPara(6, 0) = "com.adobe.acrobat.jpeg"
601 tblCovertPara(6, 1) = "jpeg"
602 tblCovertPara(7, 0) = "com.adobe.acrobat.plain-text"
603 tblCovertPara(7, 1) = "txt"
604 tblCovertPara(8, 0) = "com.adobe.acrobat.png"
605 tblCovertPara(8, 1) = "png"
606 tblCovertPara(9, 0) = "com.adobe.acrobat.ps"
607 tblCovertPara(9, 1) = "ps"
608 tblCovertPara(10, 0) = "com.adobe.acrobat.rtf"
609 tblCovertPara(10, 1) = "rtf"
610 tblCovertPara(11, 0) = "com.adobe.acrobat.spreadsheet"
611 tblCovertPara(11, 1) = "spreadsheet"
612 tblCovertPara(12, 0) = "com.adobe.acrobat.tiff"
613 tblCovertPara(12, 1) = "tiff"
614 tblCovertPara(13, 0) = "com.adobe.acrobat.xlsx"
615 tblCovertPara(13, 1) = "xlsx"
616 tblCovertPara(14, 0) = "com.adobe.acrobat.xml-1-00"
617 tblCovertPara(14, 1) = "xml"
618 tblCovertPara(15, 0) = "com.callas.preflight.pdfa"
619 tblCovertPara(15, 1) = "pdf"
620 tblCovertPara(16, 0) = "com.callas.preflight.pdfe"
621 tblCovertPara(16, 1) = "pdf"
622 tblCovertPara(17, 0) = "com.callas.preflight.pdfx"
623 tblCovertPara(17, 1) = "pdf"
624
625 Case "11", "17"
626 'Acrobat XI (11.0) ExportTask.xml + Acrobat 2017
627
628 '変換ID
629 tblCovertPara(0, 0) = "com.adobe.acrobat.accesstext"
630 '出力時のデフォルト拡張子
631 tblCovertPara(0, 1) = "txt"
632 tblCovertPara(1, 0) = "com.adobe.acrobat.doc"
633 tblCovertPara(1, 1) = "doc"
634 tblCovertPara(2, 0) = "com.adobe.acrobat.docx"
635 tblCovertPara(2, 1) = "docx"
636 tblCovertPara(3, 0) = "com.adobe.acrobat.eps"
637 tblCovertPara(3, 1) = "eps"
638 tblCovertPara(4, 0) = "com.adobe.acrobat.html"
639 tblCovertPara(4, 1) = "html"
640 tblCovertPara(5, 0) = "com.adobe.acrobat.jp2k"
641 tblCovertPara(5, 1) = "j2k"
642 tblCovertPara(6, 0) = "com.adobe.acrobat.jpeg"
643 tblCovertPara(6, 1) = "jpeg"
644 tblCovertPara(7, 0) = "com.adobe.acrobat.plain-text"
645 tblCovertPara(7, 1) = "txt"
646 tblCovertPara(8, 0) = "com.adobe.acrobat.png"
647 tblCovertPara(8, 1) = "png"
648 tblCovertPara(9, 0) = "com.adobe.acrobat.pptx"
649 tblCovertPara(9, 1) = "pptx"
650 tblCovertPara(10, 0) = "com.adobe.acrobat.ps"
651 tblCovertPara(10, 1) = "ps"
652 tblCovertPara(11, 0) = "com.adobe.acrobat.rtf"
653 tblCovertPara(11, 1) = "rtf"
654 tblCovertPara(12, 0) = "com.adobe.acrobat.spreadsheet"
655 tblCovertPara(12, 1) = "spreadsheet"
656 tblCovertPara(13, 0) = "com.adobe.acrobat.tiff"
657 tblCovertPara(13, 1) = "tiff"
658 tblCovertPara(14, 0) = "com.adobe.acrobat.xlsx"
659 tblCovertPara(14, 1) = "xlsx"
660 tblCovertPara(15, 0) = "com.adobe.acrobat.xml-1-00"
661 tblCovertPara(15, 1) = "xml"
662 tblCovertPara(16, 0) = "com.callas.preflight.pdfa"
663 tblCovertPara(16, 1) = "pdf"
664 tblCovertPara(17, 0) = "com.callas.preflight.pdfe"
665 tblCovertPara(17, 1) = "pdf"
666 tblCovertPara(18, 0) = "com.callas.preflight.pdfx"
667 tblCovertPara(18, 1) = "pdf"
668
669 Case Else
670
671 'プログラムロジックエラー
672 Convert_PDF_Format_ET_nnn2 = False
673 MsgBox "プログラムのロジックでエラー発生", , "実行エラー"
674 Exit Function
675
676 End Select
677
678 'Edit Parameters
679 '変換IDのカンマで区切った4番目を抽出
680 '例:[com.adobe.acrobat.accesstext] -> [accesstext]
681 '例:[com.callas.preflight.pdfx] -> [pdfx]
682 For i = LBound(tblCovertPara, 1) To UBound(tblCovertPara, 1)
683 If tblCovertPara(i, 0) <> vbNullString Then
684 strPara = Split(tblCovertPara(i, 0), ".")
685 tblCovertPara(i, 2) = strPara(3)
686 ' Debug.Print "tblCovertPara(" & i & ")=" & _
687 ' tblCovertPara(i, 2)
688 End If
689 Next i
690
691 '正常処理
692 Convert_PDF_Format_ET_nnn2 = True
693
694 End Function
Highlight:プログラミング言語のソースコードを構文で色分け (GUI編)
001 Public Function Get_Adobe_App_Info_nnn2( _
002 ByVal strApp As String, _
003 ByRef strPath As String, _
004 ByRef strVersion As String, _
005 ByRef strMsg As String) As Boolean
006
007 ’※当ロジックは
008 ’関数:Acrobat , Adobe Reader のインストールパスとバージョンを取得
009 ’http://pdf-file.nnn2.com/?p=767
010 ’から持ってくる。
011
012 End Function
Highlight:プログラミング言語のソースコードを構文で色分け (GUI編)
001 Public Function Get_PDF_Version_nnn2( _
002 ByVal sFilePath As String, _
003 ByRef sPDF_Version As String, _
004 ByRef lAcrobat_Version As Long) As Boolean
005
006 ’※当ロジックは
007 ’関数:「PDFのバージョン」を取得する
008 ’http://pdf-file.nnn2.com/?p=760
009 ’から持ってくる。
010
011 End Function
Highlight:プログラミング言語のソースコードを構文で色分け (GUI編)
テスト結果
1. Acrobat Pro 8.3.1 + Windows 7 64bit + Excel 2007
- 正常処理した変換パラメータ ExportTask.xml
- com.adobe.acrobat.accesstext
- com.adobe.acrobat.doc
- com.adobe.acrobat.eps
- com.adobe.acrobat.html-3-20
- com.adobe.acrobat.html-4-01-css-1-00
- com.adobe.acrobat.jp2k
- com.adobe.acrobat.jpeg
- com.adobe.acrobat.plain-text
- com.adobe.acrobat.png
- com.adobe.acrobat.ps
- com.adobe.acrobat.rtf
- com.adobe.acrobat.xml-1-00
- com.callas.preflight.pdfx
- 実行エラー
- com.adobe.acrobat.svgxpdf
- 1001実行エラー
- com.adobe.acrobat.xpdf
- 1001実行エラー
- com.callas.preflight.pdfa
- 「別のプログラムでOLEの操作が完了するまで待機を続けます」エラー
- com.adobe.acrobat.svgxpdf
備考
- 第一引数の strConvertPdf に付いて。
2次元配列で以下の様にセットする。strConvPDFfile(0, 0) = "I:¥Adobe PDF¥TEST-NO-Sec.pdf"
strConvPDFfile(0, 1) = "accesstext" '変換タイプ
strConvPDFfile(0, 2) = "TEST-NO-Sec.txt" '出力ファイル名
strConvPDFfile(0, 3) = "" '処理結果
"accesstext" はExportTask.xml にある変換パラメータ
com.adobe.acrobat.accesstext の4番目の文字列を指定。 - サンプルの Convert_PDF_Format_ET_nnn2 関数で変換パラメータ(com.adobe.acrobat.svgxpdf 等)に
対する変換後のデフォルトの拡張子は更に検討する部分もかなり有ります。- com.adobe.acrobat.jp2k -> j2k
- com.adobe.acrobat.svgxpdf -> svgx
- com.adobe.acrobat.xpdf -> pdf
- com.adobe.acrobat.spreadsheet -> spreadsheet
- com.adobe.acrobat.pptx -> pptx
注意
- 変換するための jso オブジェクトを正常に処理させるために、非常に複雑な事前チェック処理を行っています。
エラー等が出る時はコメント扱いにしている Debug.Print 命令を実行させて再検討して下さい。
※その時は当サイトページにコメントをお願いします。 - 機能で説明した出力時の拡張子は全てを動作確認していません。
- PDFをHTML変換すると、イメージ(画像等)は保存先フォルダにimageフォルダを作って、そこに別に保存されます。
この時に多数のPDFファイルをHTML変換すると、複数のHTMLファイルに対してイメージ(画像等)は同じ保存先フォルダ上に有るimageフォルダに同時に保存されます。
同じimageフォルダに保存されるのがダメな場合は、別々の保存先フォルダを個別に指定する必要が有ります。
詳細は「PDFをHTMLへ変換する上でのイメージファイルを扱う注意事項」も参照 - 出力先ドライブにCドライブは指定できません。
「Acrobat JavaScript における「Safe Path」についての注意事項」参照
動作確認環境
- Windows 98SE (WindowsUpdate) + Excel 2000 (SP3)
- Windows XP Pro (SP3 + WindowsUpdate) + Excel XP (SP3)
- Windows XP Pro (SP3 + WindowsUpdate) + Excel 2003 (SP3)
- Windows 7 64bit Home (SP1 + MicrosoftUpdate) + Excel 2007 (SP3)
< サンプル一覧 >
フォルダに2つのpdfファイルがあり、
VBAでPDFファイルをExcel(xlsx)方式で保存するコードをご教示ください。
お願いします。
先程コメントした山中です。
追記お願いします。
保存するフォルダは元々PDFが入っているフォルダに保存し、変化後のファイル名は変換前のPDFの名前と同じにできますでしょうか。
ご迷惑をおかけしますがお願いします
たびたびすいません。山中です。
もう一つ忘れてました。
PDFの中身は数ページ存在していて、エクセルファイルに変換する際は、ページをエクセルのシートごとに分けたいです。
山中さん 初めまして。
当ページの内容はメーカーが公開している情報ではありません。当サイト管理人が複数の情報を元に偶然見つけた内容です。よってネット検索をしても出てきません。もったいないので公開しました。それを前提で注意の上でご活用ください。
>・・保存するコード・・
ダウンロード・ファイル PDF-Function-yyyymmdd.zip に入っている sample-ConvertPDFFormat.xls を御覧ください。
当ページのサンプルです。
strConvPDFfile(0, 0) = "I:\Test\Test-pdf.pdf"
strConvPDFfile(0, 1) = "xlsx" '変換タイプ
strConvPDFfile(0, 2) = "Test.xlsx" '出力ファイル名
strConvPDFfile(0, 3) = "" '処理結果
で動作します。(動作しました。
strConvPDFfile(0, 3)が””ならば正常終了です。
>・・フォルダに保存し、・・名前と同じに・・
公開している当サンプルを改造すれば可能です。
>・・ページをエクセルのシートごとに分けたい・・
動作確認をしたところ、1PDFで1シート出力です。
ページ単位で1シートへの出力は出来ません。
しかし、事前に不要なページを削除(DeletePages)すれば該当ページのシート出力が可能です。ロジックは手間のかかるモノになりますが、それで対応するしか手は無いように思われます。
ご参考になれば幸いです。
管理人さん
Acrobat上で複数のPDFから中身を抽出するという作業の自動化を行いたく、検索していたところ、このサイトにたどり着きました。
pdfから文章を抽出するというのは、精度の問題から頼れるスクリプトやアプリケーションがあまりなく、Acrobatで自動化できればなあと考えていましたので、とても助かりました。
当環境(Excel2016-64bit, Acrobat DC 2019)でも無事に実行することができました。
ながとーも さん はじめまして
Twitterにコメントを頂いた方でしょうか?
とにかく、お役に立てて嬉しいです。