TOP > AcroExch.PDDoc > SetInfo [...]

説明
PDFドキュメントのInfo情報にキーとその値をセットする。
キーが無ければ追加される。
文書プロパティの概要タブにある 「タイトル」、「作成者」、「サブタイトル」、「キーワード」、「アプリケーション」、「PDF変換」、「作成日」、「更新日」の項目もこれで変更できる。
形式
VARIANT_BOOL SetInfo(BSTR szInfoKey,
BSTR szBuffer);
引数
- 第1引数(BSTR szInfoKey) :
キーワード - 第2引数(BSTR szBuffer) :
キーワードに当てはめる値
戻り値
- -1 : 成功。作成または追加出来た。
- 0 : 失敗。またはAcrobatアプリケーションがその機能をサポートしていない。
動作するバージョン
| Version | Adobe Acrobat |
備考
|
|---|---|---|
|
4
|
-
| Acrobat 4.0 ※Windows 98SE + Excel 2000 |
|
5
|
-
| Acrobat 5.0.5 |
|
6
|
-
| Acrobat 6.0.3 Pro |
|
7
|
-
| Acrobat 7.0.9 Pro Acrobat 7.1.4 Pro |
|
8
|
OK
| Acrobat 8.1.2 Pro |
|
9
|
-
| Acrobat 9.3.2 Extended |
|
10
|
-
| Acrobat X (10.1.8) Extended |
|
11
|
OK
| Acrobat XI (11.0.14) Pro |
- OK = 動作する。
- NO = 動作しない。 戻り値が0を返す。
- - = 未確認。
サンプル1:ExcelのVBA
説明:PDFドキュメントにキーワード "PS" に値 "HogeHoge" をセットする。
- F8キーでステップ実行しながら動作確認する。
- 事前に参照設定をする。
001 Sub AcroExch_PDDoc_SetInfo()
002
003 Dim objAcrobatPDDoc As New Acrobat.AcroPDDoc
004 Dim lRet As Long
005 Const CON_FILE As String = "E:¥Test01.pdf"
006 'write changes only.
007 Const PDSaveIncremental = &H0
008
009 'PDFオブジェクトをオープンする。
010 '注意)Acrobatは画面に表示されない。
011 lRet = objAcrobatPDDoc.Open(CON_FILE)
012
013 'キーワード"PS"に値"HogeHoge"をセットする。
014 lRet = objAcrobatPDDoc.SetInfo("PS", "HogeHoge")
015
016 'PDFファイルの変更部分のみ保存する。
017 lRet = objAcrobatPDDoc.Save(PDSaveIncremental, _
018 CON_FILE)
019
020 'PDFオブジェクトを解放する。
021 objAcrobatPDDoc.Close
022 Set objAcrobatPDDoc = Nothing
023
024 End Sub
Highlight:プログラミング言語のソースコードを構文で色分け (GUI編)
実行結果
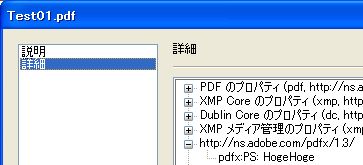
サンプル2:ExcelのVBA
説明:文書プロパティの概要タブにある 「タイトル」、「作成者」、「サブタイトル」、「キーワード」、「アプリケーション」、「PDF変換」、「作成日」、「更新日」の項目を更新する。
001 Sub AcroExch_PDDoc_SetInfo2()
002
003 Dim objAcrobatPDDoc As New Acrobat.AcroPDDoc
004 Dim lRet As Long
005 Const CON_FILE_OLD As String = "I:¥Adobe PDF¥test-1.pdf"
006 Const CON_FILE_NEW As String = "I:¥Adobe PDF¥test-2.pdf"
007
008 'PDFオブジェクトをオープンする。
009 '注意)Acrobatは画面に表示されない。
010 lRet = objAcrobatPDDoc.Open(CON_FILE_OLD)
011
012 '文書プロパティのタイトル
013 lRet = objAcrobatPDDoc.SetInfo("Title", "私は誰?")
014 Debug.Print "SetInfo(""Title"")=" & objAcrobatPDDoc.GetInfo("Title")
015 '文書プロパティの作成者
016 lRet = objAcrobatPDDoc.SetInfo("Author", "真田幸村")
017 Debug.Print "SetInfo(""Author"")=" & objAcrobatPDDoc.GetInfo("Author")
018 '文書プロパティのサブタイトル
019 lRet = objAcrobatPDDoc.SetInfo("Subject", "鯛がドラマ")
020 Debug.Print "SetInfo(""Subject"")=" & objAcrobatPDDoc.GetInfo("Subject")
021 '文書プロパティのキーワード
022 lRet = objAcrobatPDDoc.SetInfo("Keywords", "エラソー,夜八時,ネギは好き?")
023 Debug.Print "SetInfo(""Keywords"")=" & objAcrobatPDDoc.GetInfo("Keywords")
024 '文書プロパティのアプリケーション
025 lRet = objAcrobatPDDoc.SetInfo("Creator", "Hogesoft Word 3001")
026 Debug.Print "SetInfo(""Creator"")=" & objAcrobatPDDoc.GetInfo("Creator")
027 '文書プロパティのPDF変換
028 lRet = objAcrobatPDDoc.SetInfo("Producer", "Hogesoft Word 3001 Convert")
029 Debug.Print "SetInfo(""Producer"")=" & objAcrobatPDDoc.GetInfo("Producer")
030 '文書プロパティの作成日 (2001/12/24 10:55:58)
031 lRet = objAcrobatPDDoc.SetInfo("CreationDate", "D:20011224105558+09'00'")
032 Debug.Print "SetInfo(""CreationDate"")=" & objAcrobatPDDoc.GetInfo("CreationDate")
033 '文書プロパティの更新日 (2014/04/23 19:30:07)
034 lRet = objAcrobatPDDoc.SetInfo("ModDate", "D:20140423193007+09'00'")
035 Debug.Print "SetInfo(""ModDate"")=" & objAcrobatPDDoc.GetInfo("ModDate")
036
037 'PDFファイルを別名で保存する。
038 lRet = objAcrobatPDDoc.Save(1, CON_FILE_NEW)
039
040 'PDFオブジェクトを解放する。
041 objAcrobatPDDoc.Close
042 Set objAcrobatPDDoc = Nothing
043
044 End Sub
Highlight:プログラミング言語のソースコードを構文で色分け (GUI編)
実行結果

動作確認環境
- Windows XP Pro(+ SP3) +
Acrobat 8.1.2 Pro + Office 2003 + MicrosoftUpdate - Windows 10 64bit Pro +
Acrobat XI Pro + Office 2007 + WindowsUpdate
備考
- PDDoc.GetInfo
文書プロパティの概要の部分を取り出す。 - サンプル
文書プロパティの開き方・タブの部分を変更するサンプル。 - 関数:PDFの文書プロパティを更新
SetInfo メソッドでは正常にPDFの文書プロパティを更新できない時に参考にする関数です。
< 戻る >
seizi さんへ。
コチラからの返答内容が複雑で内容も多岐に渡っています。
現在、返答内容の整理中です。
一時的に返答内容を最小限にするために、以下5点を質問をさせて下さい。
① CPDFのソフトの使用は可能でしょうか。このソフトはVBAからも制御可能です。
② PDFのプロパティ更新はPDFファイル毎に異なるのでしょうか。プロパティの更新内容が数種類で固定なのでしょうか。
③ ダブルクォーテーションにはそれなりの意味が有るみたいですが、それを無視してでも行いたいのでしょうか。
それで内部の設定が変わる部分は確認済みですが、その影響が最終的にどこになるのかは確認は取れていません。
④ PDFのプロパティには「開き方」タブの部分が有ります。この値を書き換えても問題は無いでしょうか。そこは各PDFファイルが持っている内容のままに変更せずに置いときたいのでしょうか。
⑤ PDFのプロパティ更新は追加では無く上書きでしたい、と言う事でしょうか。
以上、お願い致します。
管理人さんへ。
ご質問の内容についてですが、
①こちらは、個人で使用するものではないので、ライセンスの問題があるのかなと思っております。2バイト文字への対応が出来ていないようなコメントがありましたので、確認していません。
②内容はファイル毎に異なります。既存の情報を読み込み個別に変更して書き戻す処理を行いたいと考えております。
③Acrobatで直接入力すると"が入りません。"が入る場合と入っていない場合の違いが分からないのですが、"で囲まれているとキーワードは一つになるのではないかと思った次第です。
④変更したい内容は、概要タブにある4項目のみとなります。それ以外の変更は基本的に考えて降りません。
以上、よろしくお願いいたします。
⑤が抜けていました。すみません。
⑤はおっしゃる通り上書きしたいです。
キーワードで追加された分だけしかgetinfoで取り出せないのをどうにか解決出来ないかと思っています。
pdftk等で書き出しても全部書き出してくれないです。
よろしくお願いいたします。
seizi さんへ。
中間報告です。
深く意識しなかった部分だったので再調査、再検討するのに時間が掛かっています。
最終結論にはなっていませんが「可能」かもしれない、という方向で進めています。
今は技術的に「可能」と言える為のテスト検証をしています。
基本的な考えとなるロジックは以下です。
'メタデータの更新
Sub Demo()
Dim objAcroAVDoc As New Acrobat.AcroAVDoc
Dim sMetaData As String
Dim sMeta
Dim lRet As Long
'PDFのオープン
lRet = objAcroAVDoc.Open("D:\Test.pdf", "")
'メタストリームの更新
With objAcroAVDoc.GetPDDoc.GetJSObject
sMetaData = .metadata
'★sMetaDataのXMPストリームを更新(編集)する★
.metadata = sMetaData
End With
'文書ディクショナリ(Info)の更新
With objAcroAVDoc.GetPDDoc.GetJSObject
'タイトル
.info.Title = "AA"
'作成者
.info.Author = "BB"
'サブタイトル
.info.Subject = "CC"
'キーワード
.info.Keywords = "DD"
End With
objAcroAVDoc.Close 1 '保存しないで閉じる。実際はココで保存。
Set objAcroAVDoc = Nothing
End Sub
まだテストしないと結果が見えませんが、実際は上記の20倍以上のロジックが必要になると予想しています。
PDFのプロパティのタイトル~キーワードの部分の情報はメタデータに入っています。そのメタデータはメタストリームと文書情報ディクショナリの構成になっています。
以下の情報をメインで参考にしました。
・メタデータ (Metadata)
・Acrobat ヘルプ /PDF のプロパティとメタデータ
・
英語:Adobe:Importing Metadata into PDF Documents・JavaScript for Acrobat API Reference Adobe Acrobat SDK バージョン 8.0
「上書き」する為にはこのメタデータを直接に更新する必要があると言う結論になりました。ただしこの更新がテストでは細かい点でイロイロと問題が出ます。知らない事+分からない事が多すぎるのも問題です。
「ダブルクオーテーション」「手入力」「追加される」の問題は「メタデータの存在とその形式」、「PDFの内部構造」、「プラス・過去の経験」から予測すると結果がある程度は見えます。但し説明する材料を探し出す時間と余裕が私には無いです。※「手入力」は当サイトでは専門外分野・・。
よって、「値の取得」と「上書き更新」のみに専念する予定です。
技術検証が出来ましたら、結果とそのサンプルを公開します。
次のコメント予定は来週か、な?
管理人さん。
中間報告ありがとうございます。
やはりxmlで格納されているメタデータを
直接書き換えなければ対応できないようですね。
javascriptを使った処理も最初に考えてみていたのですが、
値の取得が出来ないのではないかと思い早々に諦めました。
次に、メタデータをxmlで取得するロジックがどこかにあったので
それを使ってxmlにしたのですが、xmlデータが複数出力されました。
これを直接更新できればとは思ったのですが、
VBAでは無理かと諦めました。
次に、EXCEL-DNAを使用してitextsharpで対応できないかと
チャレンジし、取得と上書き更新はできましたが
キーワードに読点やカンマが入ると
"で囲まれて二重にしまいました。
セミコロンだと"は入らず二重にもならなかったのです。
また、ファイルサイズが倍以上になってしまうということで、
こちらも諦めました。
手入力については、
手入力すると取得と更新が正常に行えないので
問題無く取得と更新ができるようにしたいのです。
引き続き、結果が出ましたら
お願いいたします。
seizi さんへ。
>次に、メタデータをxmlで取得するロジックが・・・
>・・・
>VBAでは無理かと諦めました。
諦めないで下さい!
前のコメントのロジック
With objAcroAVDoc.GetPDDoc.GetJSObject
sMetaData = .metadata ’メタデータの取得
'★sMetaDataのXMPストリームを更新(編集)する★
.metadata = sMetaData 'メタデータの更新
End With
上記VBAだけでXMLの更新が直接出来ました。
テストでは更新できました!
sMetaData にXMLが入っています。
但し、「文書ディクショナリ(Info)の更新」も後の処理で行わないとXMLが正しく反映されない、みたいです。
理由は不明です。
管理人さんへ。
ありがとうございます。
メタデータから書き出したxmlを元に
別のxmlを作成して読み込んでみましたが
.metadataを更新にしてもxmlが更新されませんでした。
.metadata = ""
ですと削除されるのですが。
削除してから「文書ディクショナリ(Info)の更新」で
値を再度入れると、"で囲まれてしまいます。
バタバタしてきたので
少しずつですが、頑張ってもう少しやってみます。
seizi さんへ
昨日はテスト結果が不良で気分は凹状態でした。
どうしても作成者とキーワードの値が2つ以上存在すると変になります。
テスト結果はseiziさんとタブン同じでしょう。
>別のxmlを作成して読み込んでみましたが・・
Acrobatから出力したXMPファイルとVBAでの .metadata でのフォーマットが少し違うからです。要素「rdf:Description」の内部の値のフォーマットが違います。それは昨日のテストで気が付きました。
例:XMPのファイルは
・<xmpMM:DocumentID>***</xmpMM:DocumentID>
例:.metadata のフォーマットは
・xmpMM:DocumentID="***"
>.metadata = ""
それをやると他のメタデータも消えてしまいます。
でも、まだ諦めてはいません。
何か見落としているような気がするので、見直しです。
※XMPの最新バージョンの資料
http://www.adobe.com/devnet/xmp/sdk/eula-cc20168.html
Agree and download XMP Toolkit SDK CC-2016.7 (XMP-Toolkit-SDK-CC201607.zip, 38.7 MB)
管理人さんへ。
仕様を確認しても英語でちんぷんかんぷんですw
まず、xmpの内容についてですが、
先頭行にxmlの宣言を入れていましたが、
先頭行を削除したら更新されました。
そして、Acrobatのプロパティから
その他のメタデータを確認して試行錯誤したところ
キーワードでダブルクォーテーションと二重になる原因も分かりました。
その他のメタデータの詳細にある
PDFのプロパティにあるpdf:Keywordsは一つですが
Dublin Coreのプロパティにあるdc:subjectが複数になっていました。
そこで、pdf:Keywordsの内容をdc:subjectに入れる際に
「、」で分割してrdf:liをキーワード分作成したところ解決しました。
なお、xmpMM:DocumentIDの記述ですが、
rdf:Descriptionの記述方法の違いだけでどちらでも問題ないようです。
諦めていましたが、VBAで対応できることが確認でき
かなりスッキリしました。
ありがとうございました。
xmlのソースはコメントに入れられないのですか?
入れと送信するとエラーがなってしまいます。
seizi さんへ。
一度、頭を冷やした所、少し気が付いた所が出てきたので後で確認しようかと思っています。
>xmlのソースはコメントに入れられないのですか?
XMLと言えども<・・>等の文字はHTMLコードの一部と見なされるので許可されたタグ以外はセキュリティの関係で拒否します。これはサイトへの攻撃を防ぐために解除出来ません。(出来ますが・・) <>の文字部分をエンティティ処理すれば入力は可能です。それか<>の文字のみ全角の文字にすればOKです。
判明した技術のメモ:
・XMPデータはPDF内で複数存在する。画面には最新の内容が表示される。
↑バイナリーエディタで確認済み。
・最適化をすることでXMPデータを1つにする事が出来る。
seizi さんへ。
関数:PDFの文書プロパティを更新
上記は今までの検証結果を全てまとめたものです。
seizi さんの希望する形にはなって無いのが残念ですが、少しは参考になると思っています。
ご検証ください。
管理人さんへ。
確認させていただきました。
十分すぎる結果です。
ありがとうございました。
seizi さんへ
チョット待ってください。
サンプルの貼り付けが変です。
しばらくお待ち下さい。(汗
”<” と ”>” 文字が許されないHTMLタグとして誤認識され削除されている部分が多数有ります。
サンプルを貼り付け直しましたので、これ以降に再度ご検証ください。
注意:サンプルは"<"、">"文字を全角から半角に一括変換してご利用下さい。